A $3,000,000 Dropdown
TLDR; Shameless Plug
Sentry is excited to offer EU Data Residency (from Frankfurt, Germany) to our customers on **all** plan tiers and at no extra cost. Fill out our form for early access or wait for the GA planned in December.
On to the technical goodies…
The Project
Almost 2 years ago, Sentry embarked on a project to bring true data residency to our customers. We decided to do it the hard way.
We’ve been fully compliant with GDPR through data processor contracts, but we wanted to side-step the lawyers and enable customers to truly host their data in the EU. Many Sentry users, big and small, have been self-hosting Sentry because we were unable to provide in-jurisdiction data storage for them.
Superficially, supporting the EU is as simple as adding a dropdown to our organization creation flow. We did in fact do that, but there is a mountain of work that happened behind the scenes that we want to share!
This is the $3M dropdown in the Sentry organization creation flow that sets where your customer data is stored:
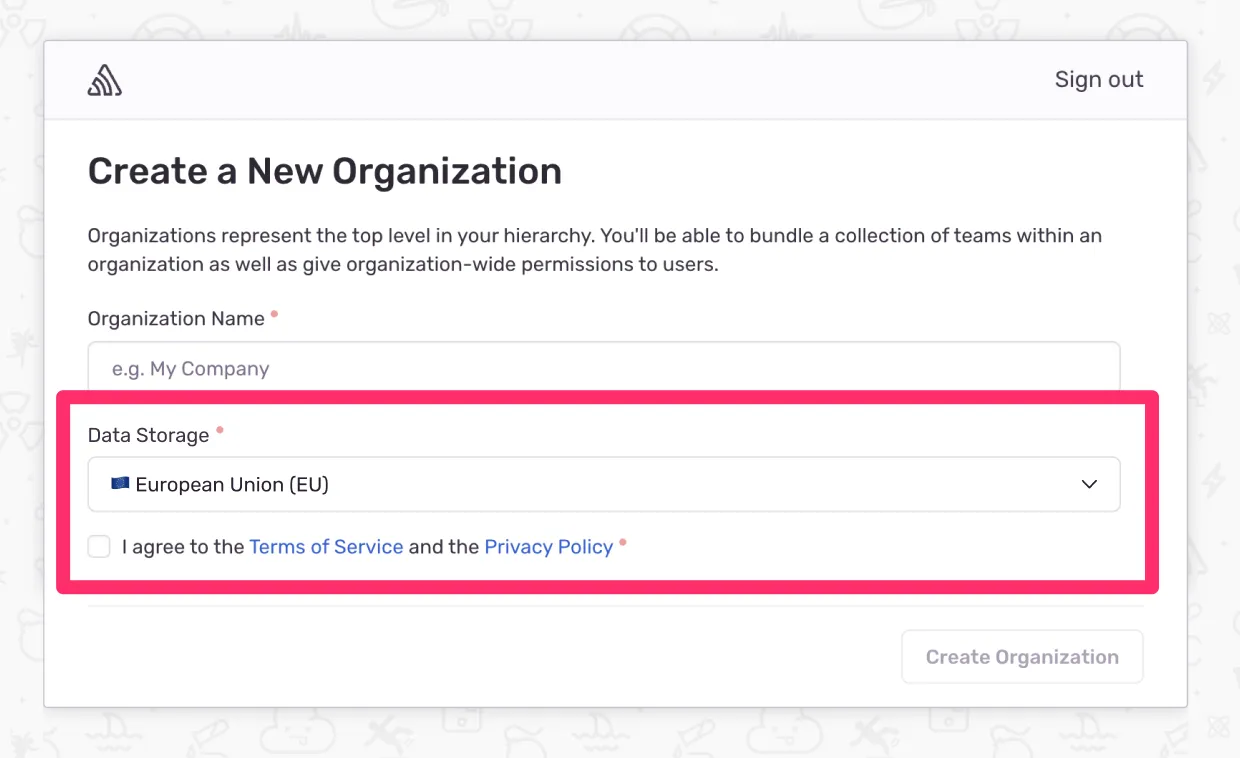
💰 ~15 people working part or full time over >18 months in San Francisco and Toronto easily tops $3M.
Optimizing for User Experience
One of the primary goals of this project was to deliver a great user experience for our customers. This drove most of our decision-making.
A simple implementation would’ve involved deploying a completely disjointed instance of Sentry in the EU. Unfortunately, this would’ve been a terrible user experience for many customers.
You’ve probably experienced the bad UX I’m talking about with other products. Every time you want to log in, you have to tell them your email address or the name of your organization, then they send you a link to the right URL where you can actually log in.
We wanted to avoid that rigamarole – for several reasons. About half of Sentry’s users are in multiple Sentry organizations, and those organizations can now be in different data centers. Imagine having to wait for an email link every time you wanted to switch organizations?
We wanted to do better. We wanted to maintain your ability to seamlessly toggle between Sentry organizations anywhere in the world.
We also have 1000s of organizations that share the same 3rd party integration target with multiple Sentry organizations. Sometimes several teams within a company will create their own Sentry orgniazations but share a single GitHub account or Slack workspace. Or a parent company can have many subsidiaries (each with their own Sentry organization) that all share a Jira instance. We didn’t want to break any of these customer workflows just because customers opt to have organizations in multiple locales.
We worked hard to design a solution that maintained these optimal experiences, and that was as backward compatibile and as fault-tolerant as possible.
An architecture that optimizes for UX
First, some context
Sentry is a monolithic Python Django application deployed in several form factors (web servers, Kafka consumers, Celery workers, etc). The application is backed by several PostgreSQL and Redis clusters, Google Cloud Storage, Snuba and Clickhouse clusters, and a bunch of other services like Relay and Symbolicator that are associated with our processing pipeline.
🪚 Our job was to take this monolithic hydra of an application and surgically divide all the pieces that need to be centralized from all the customer data that needs to be localized all while the application is running and 100ish other engineers are working on the project.
Some stats to illustrate the scope of the sentry monolith:

Our approach
The most important thing we did was to articulate a clear difference between Sentry user data (its users) and Sentry’s customers’ data (event data). Customer event data must never leave the region it was sent to, but Sentry user data has to be reachable everywhere.
Splitting the data model
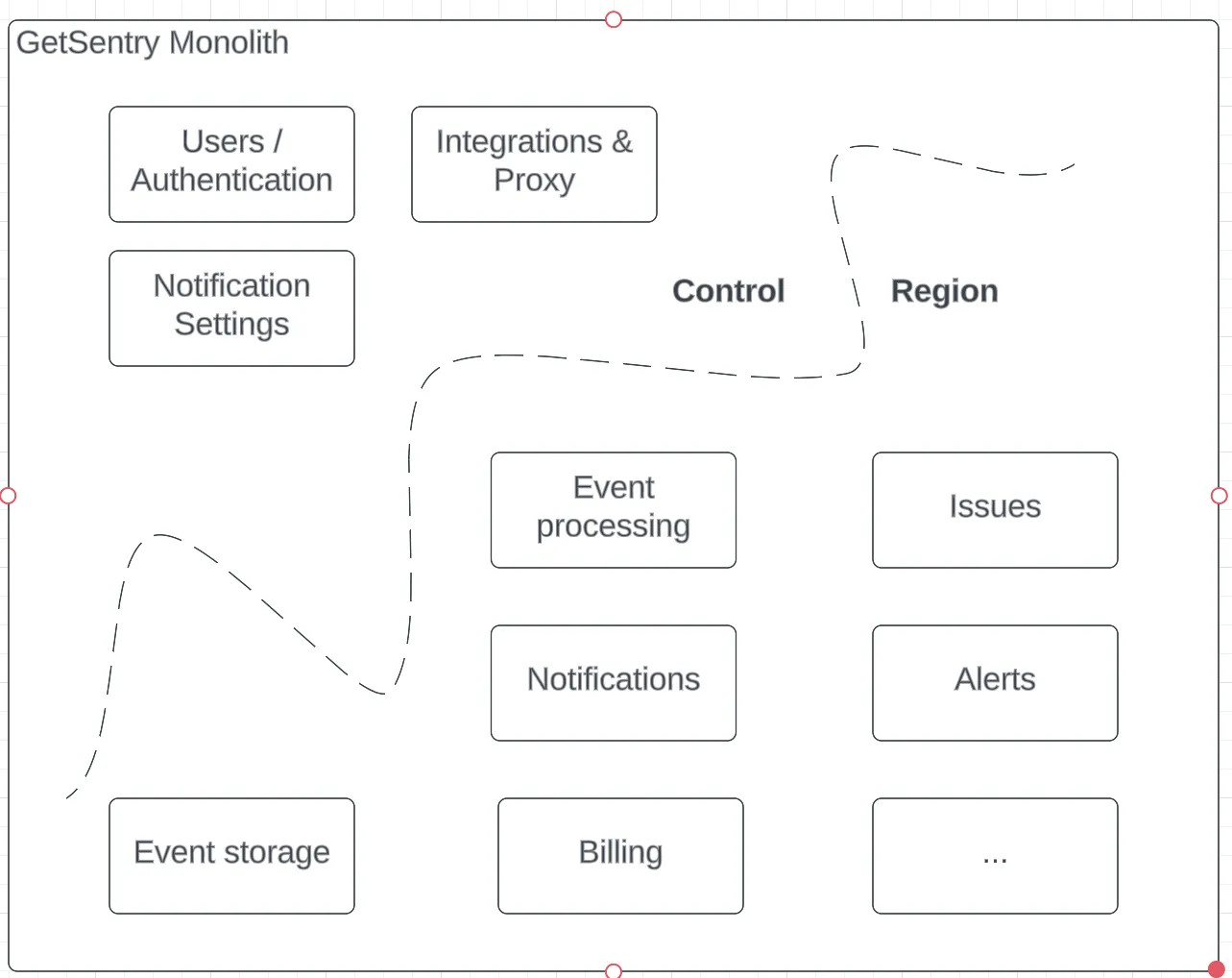
Given those constraints, we began by introducing the concept of “silos”. A single “control silo” contains globally unique data and many “region silos” contain Sentry’s customer’s data.
The control silo holds globally unique information like organization data, user accounts, slugs, and integration configuration. The region silos contain all of an organization’s events, projects, and other customer-specific information.
We then assigned each model to a silo and went about breaking all foreign keys between models located in different silos. This required roughly 80 migrations as well as refactoring all queries that joined data across silo boundaries to either fundamentally change how they work or replace them with RPC calls.
Cross silo interaction
Customer data cannot be fetched from region silos, which is the key principle of the design, but there are lots of cases where region silos need user information to check permissions or fetch notification settings to properly send an alert. To handle these cases, we ended up building two primary mechanisms: RPCs and a transactionally written event queue (aka an “outbox”) that we use to ensure eventual consistency.
Remote Procedure Calls
We ended up building a fairly standard RPC implementation that allows us to define a pure python interface that accepts simple dataclasses as arguments, then we provide a single concrete implementation of the interface. We have some decorators and helper methods that wrap up the interface and autogenerate an HTTP client implementation that handles arguemnt serialization, etc and connects to our RPC endpoint that re-marshals the data and handles dispatching to the concrete implementation.
Why not GRPC?
We strongly considered it, but adopting a code gen tool for this was a bit controversial internally, and this wasn’t that hard to implement, so we just built it 🤷.
RPC Versioning
Breaking API changes can be a big problem. Particularly when we have to run different versions of Sentry all over the world in a backward compatible way. That’s why we are building a tool that publishes the OpenAPI spec for our RPC interfaces and can detect incompatible version drift (like removing arguments or adding arguments without a default). In practice, so far at least, these APIs don’t change much, so we’ve been prioritizing shipping this to customers, but we’ll be circling back to ship this to ensure that all of our cross-silo communication remains stable.
Cross Region Replication
We had some hearty debate about how to handle data replication where we needed it. We wanted to strike the right balance between network efficiency, explicitness, and ease of correct use. We didn’t want to require intervention from our ops team to replicate a new table, but we also didn’t want it to be too easy for developers to move data around that they shouldn’t be moving. Explicitness was key to the implementation so we could confirm correctness.
Why not Change Data Capture (CDC)?
Sentry has a lot of wildly varying deployment modes that we need to handle: self-hosted, development environments, test suites, single tenants, and production SaaS. Our replication needs also occasionally involve business logic that needs to be tested. Between the operational complexity and our need for custom business logic, we opted to fully define our replication implementation within the application logic so that it would just work everywhere and be easy to test.
Cross silo synchronization
Webhook Proxying
Sentry receives webhooks from many third parties, ranging from repository providers like GitHub to payment processors like Stripe. Many of these integrations only allow for a single webhook destination. This created a significant challenge for our multi-region architecture: where should webhooks go? We chose a design that receives all integration webhooks in the Control Silo. Once received, webhook payloads are stored as outbox messages which are delivered to the relevant region as if it came from the integrating service directly. This design allowed us to avoid rewriting complex webhook handling logic and focus our efforts on extracting routing information from webhooks and proxying hooks to the relevant region in an eventually consistent way.
3rd Party Integrations
Sentry allows third party integrations to be shared across organizations. This was no problem when all requests to the third party originated from the same place, but now these organizations can be in different regions. This causes a problem: any of the requests to a third party from any region could trigger an OAuth token refresh that other silos need to be immediately aware of. Eventual consistency driven by our outbox system is insufficient for meeting this requirement.
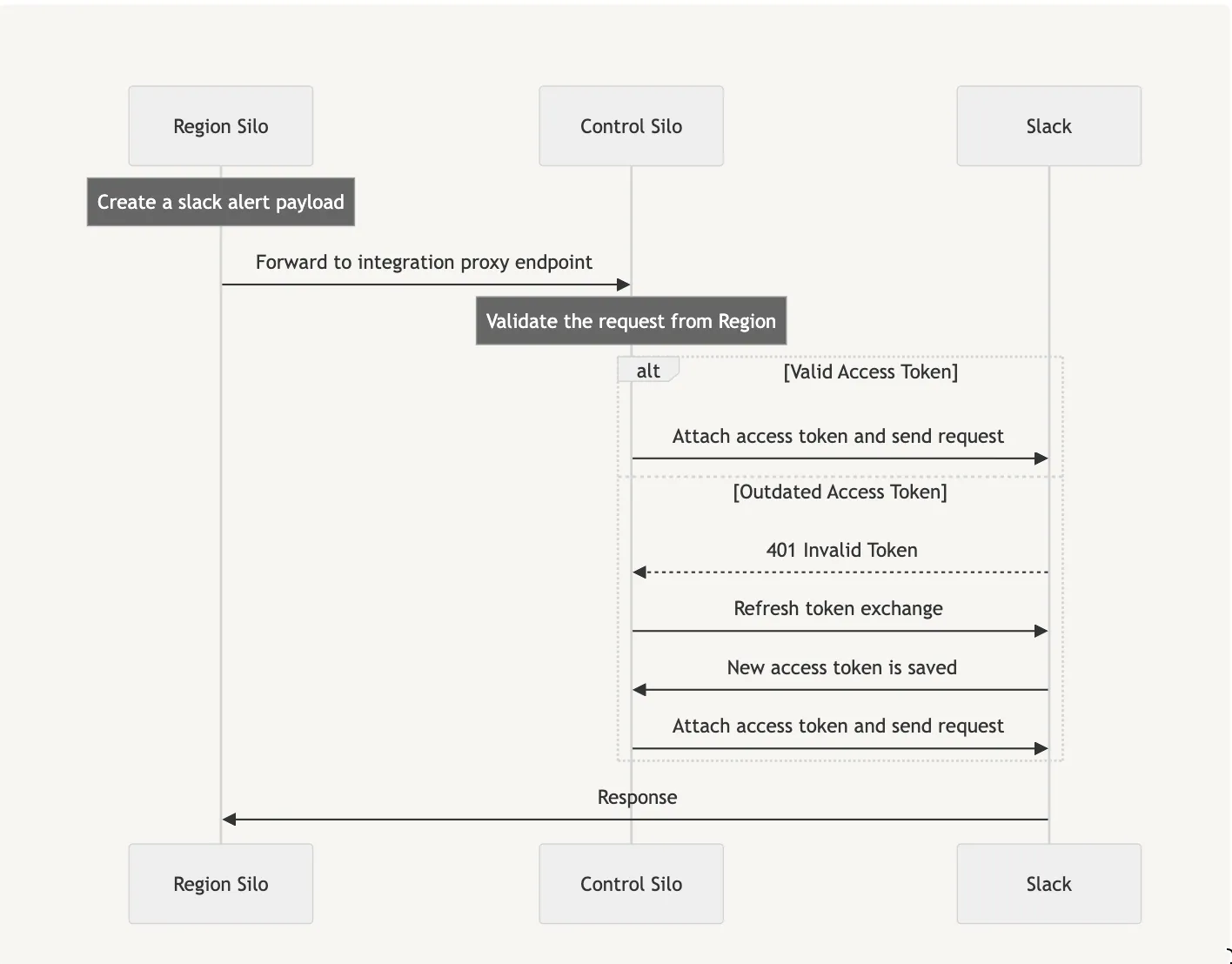
In order to provide this synchronization, we built an OAuth aware 3rd party proxy that handles token refreshes and allows us to maintain a single source of truth for OAuth tokens. The trade off for correctness here is that all 3rd party API traffic has to go through this proxy that lives in the control silo.
Learnings & Challenges
This post was only able to scratch the surface of the many interesting challenges we encountered in this project. We’ll be covering many of these topic in more detail in an upcoming blog series after we go live.
| Customer Domains | Deploy Pipelines |
| Upgrading Columns to BigInt | Audit Logs & User IP Records |
| Distributed ID Generation | Admin UX Changes |
| Cross Region Replication | Move Marketo Domain |
| Control Silo Webhook Forwarding | Update ETL for Control Silo |
| Endpoint Allocation & Enforcement | Update ETL for Region Silos |
| Model Allocation & Enforcement | Dangerous Migrations in Multi-Region |
| API Gateway | Relay in Each Region |
| Infra Provisioning for Regions | Datadog Observability Consolidation |
| Infra Provisioning for Control | RPC Implementation |
| Region Selection UX | CI with Logically Split DBs |
| New APIs for Non-Organization Resources | CI with Actually Split DBs |
| Feature Flagging Across Regions |
If there’s anything specific you’d like to hear more about, hit us up on Discord or Twitter!
How do I get it?
We’re currently in the process of launching the new EU region. If you’re interested in early access, you can sign up here https://sentry.io/trust/privacy/#data-residency-form.
We also have new tooling coming soon to support relocating organizations from self-hosted to EU/US region as well as between the EU/US regions. We’ll update here as soon as it’s available.