Building Sentry: Symbolicator
Welcome to our series of blog posts about all the nitty-gritty details that go into building a great debug experience at scale. Today, we’re looking at Symbolicator, the service that processes all native crash reports and minidumps at Sentry.
At Sentry, we live to provide the best user experience possible. Over the years, this has led us to optimize Sentry for various platforms and frameworks, such as .NET, Java, Python, JavaScript, and React Native. In addition to the SDKs you use every day to collect events and context from your apps, we also built a fair amount of server-side processing to provide you with high-quality reports.
Over two years ago, Sentry started supporting its first native platform: iOS. Since then, we’ve added support for many other platforms via minidumps and recently introduced our own SDK for native applications to make capturing all that precious information more accessible.
Now, the time has come to lift the curtain and show you how we handle native crashes in Sentry. Join us on a multi-year journey from our first baby-steps at native crash analysis to Symbolicator, the reusable open-source service that we’ve built to make native crash reporting easier than ever.
Native code is different
Building a solution for native apps has been a particularly interesting task for us. Due to the lack of a runtime, extracting stack traces or other useful context information is much harder. Without a safety net, native applications can easily crash to a point beyond recovery, with little possibility of sending a crash report to Sentry. Build systems are also vastly different from other ecosystems, as there are many more choices and configuration options, making it harder to provide a streamlined solution.
The common ground for all native applications is that they compile to machine code. At this level, variable and type names are typically gone. Function names only exist in a mangled form, or even optimized away completely. Call stacks of every running thread exist as binary memory regions, with a format defined by the ABI of the CPU or even left up to the compiler implementation.
When native applications crash, for example, due to invalid memory access or illegal instruction, the operating system kernel stops their execution. Depending on the system, a signal is sent to the application, which can be used to react to the crash and run crucial operations before terminating completely. However, since signal handlers aren’t allowed to run any unsafe code, their capabilities are quite limited.
Debuggers — and also Sentry — are presented with the challenge of reading a stack trace from the threads’ call stack memory region, symbolicating them into human-readable function names, and, finally, enriching them with additional information.
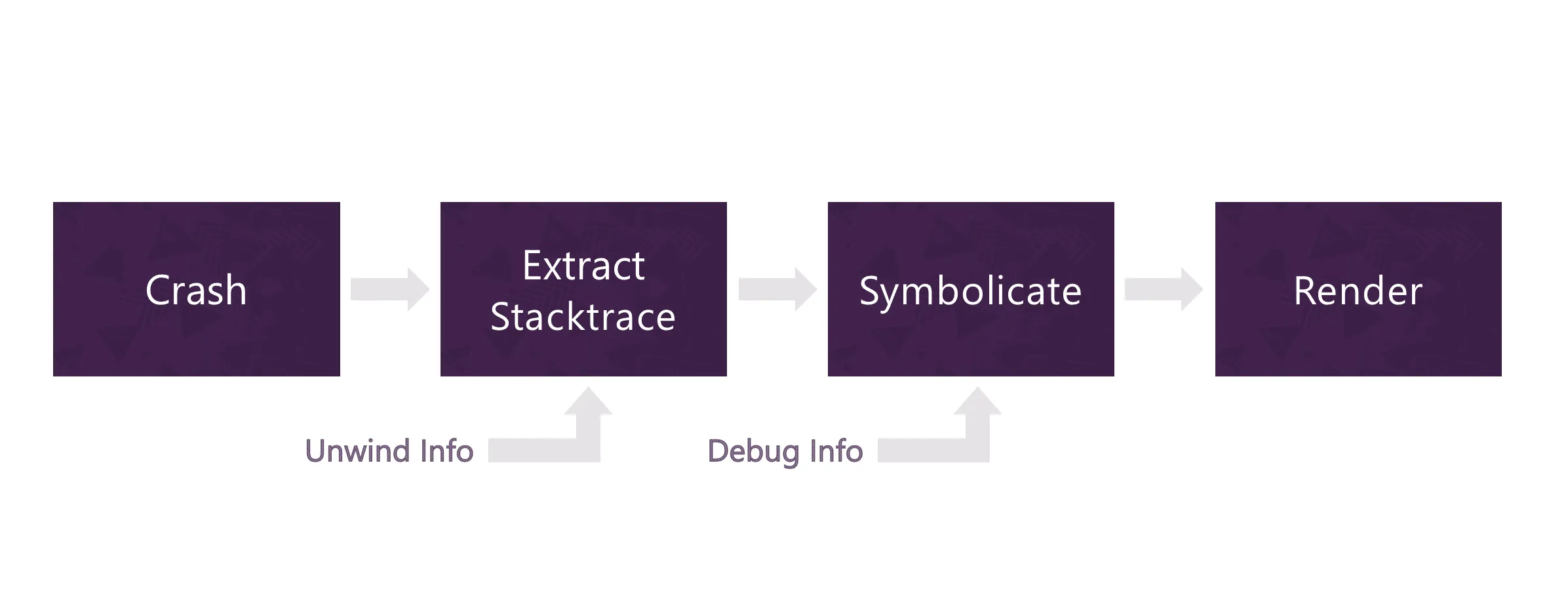
Stacking your cards frames
In our initial implementation for iOS, we relied on an open-source framework called KSCrash to create a signal handler that catches crashes and computes stack traces. Since iOS is particularly restrictive, we dumped this information into a temporary location and let the application terminate. On the next application launch, our iOS SDK created an event and sent it off to Sentry.
To understand how KSCrash works, we have to take a look at stack memory: the call stack is a continuous list of variable-length frame records. Such a record is pushed when a subroutine is invoked and contains its parameters, local variables, and temporaries. More importantly, however, it includes a special address — the so-called return address, which is an instruction pointer telling the CPU where to continue execution once the subroutine completes.
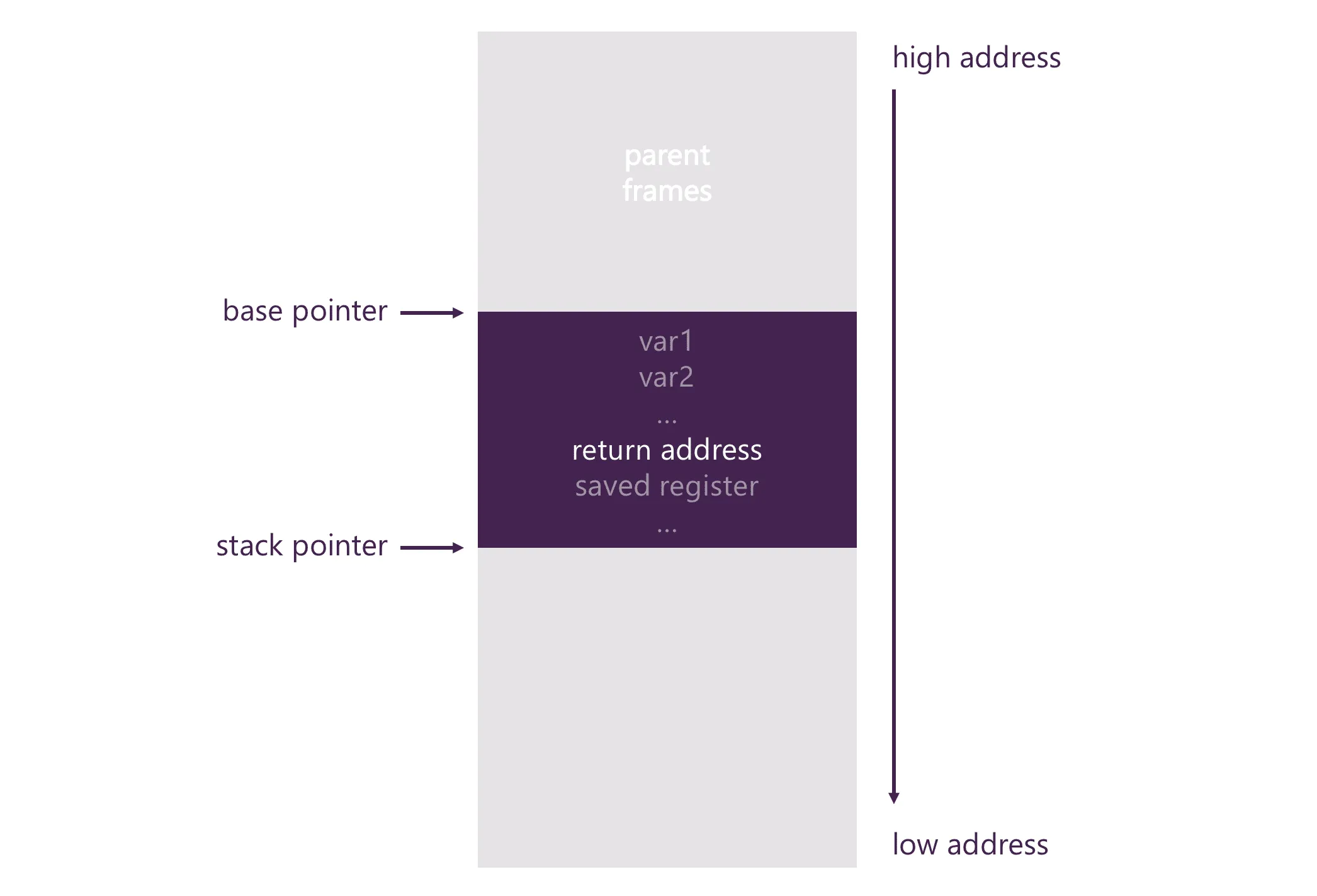
At any given time, the CPU keeps track of two special pointers in its registers: the current code instruction that is being executed, and the top of the stack. By looking at the top stack frame, one can obtain the return address, i.e., the instruction pointer of the parent frame once it returns. Repeat that for all frames, and you’re left with your stack trace, right? Well… almost.
What we actually have is just the list of return addresses. As a developer, however, you’re interested in where your function was called, and, luckily, there are heuristics to get the actual caller address from the return address. The simplest would be to simply subtract one instruction, as in many cases the call and the return point are subsequent.

Walking with dinosaurs
Life is not that simple. In order to walk through frame records in the call stack memory, you need to know the size of each individual frame. To make this easier, compilers emit a frame pointer into every frame pointing to the parent frame. Since the frame pointer is not needed during actual execution, it is usually omitted in release builds to save a few bytes.
Fortunately, debuggers aren’t the only tools interested in being able to walk up the stack. Welcome to the stage: exception handlers. That’s right; every time you throw an exception, some built-in routine needs to unwind the call stack until it hits a frame with an exception handler.
For this purpose, compilers are emitting so-called unwind information, or call frame information. Unwind information indicates the size and contents of all function frame records so that the application or a debugger can walk the stack and extract values like the return address. The information is stored in a condensed binary form in a separate section of the executable so that it can quickly be processed. Convenient, right? Well… almost.
There are still vast differences between various operating systems and CPU architectures. The effective strategy for stackwalking depends on a combination of both and requires reading unwind information in various formats. Unfortunately, the information emitted by compilers is not always accurate or complete due to specific optimizations. Also, certain programs manually manipulate the stack, which can lead to entirely different effects.
At Sentry, we’ve incorporated unwind information handling into our symbolic library. It is built on top of amazing open-source Rust libraries goblin and pdb, which provide the lower-level parsing of the different file formats and binary representation. Over time, we also had the pleasure to contribute to those libraries and fix certain edge cases or implement recent additions to the file standards.
For platforms other than iOS, we use Google’s Breakpad library to generate minidump crash reports and then process them on our servers. This library contains stack walkers for the most prevalent CPU architectures, which we feed with the unwind information they require to do their job.
(Debug) information is gold
So far on our journey to native crash analysis, we have obtained a list of instruction pointer addresses. That’s barely a stack trace you could use to debug your applications. You need function names and line numbers.
The final executable no longer needs to know the names of variables or the files that your code was declared in. Sometimes, not even function names play a role anymore. To ensure that developers can still inspect their applications, compilers, therefore, output debug information containing data to connect the optimized instructions with their source code.
However, this debug information can get large. It’s not uncommon to encounter debug information 10 times the size of the executable. For this reason, debug information is often moved (or stripped) to separate companion files. They are commonly referred to as Debug Information Files, or Debug Symbols. On Windows, they carry a .pdb extension, on macOS, they are .dSYM folder structures, and, on Linux, there is a convention to put them in .debug files.
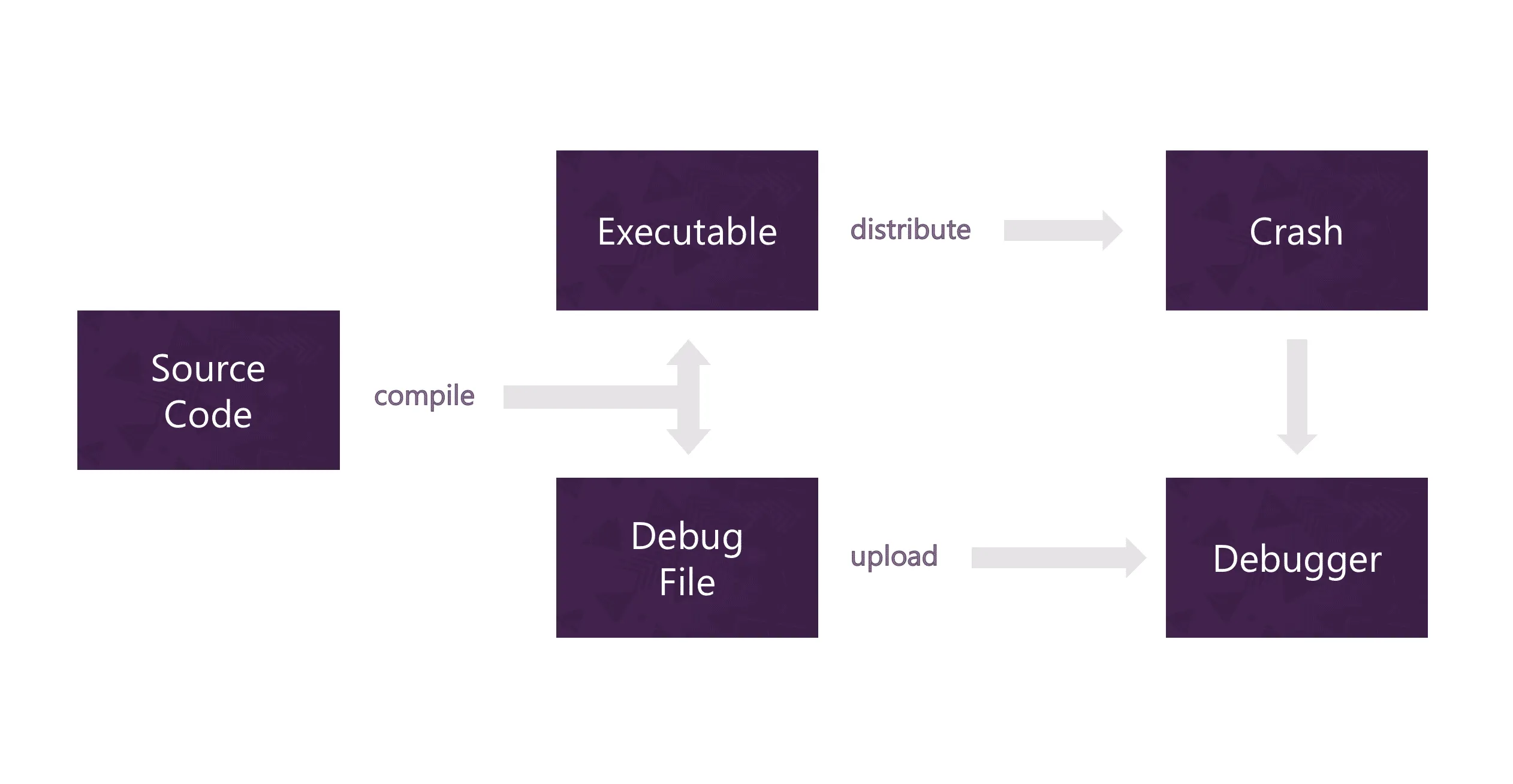
The internal format of these files also varies — while macOS and Linux generally use the open-source DWARF standard, Microsoft implemented their proprietary CodeView that was eventually open-sourced at the request of the LLVM project.
At the heart of each debug information file are tree-like structures explaining the contents of every compilation unit. They contain all types, functions, parameters as well as variables, scopes, and more. Additionally, there are mappings of these structures to instruction pointer addresses in the source code as well as the file and line number where they are declared.
This is precisely the information needed to turn instruction addresses into human-readable stack traces. And, this is essentially what debuggers do; they look up the respective instruction address in the debug file and then display all sorts of stored information. For example, inline functions that no longer have their own stack record as their code has been moved into another function.
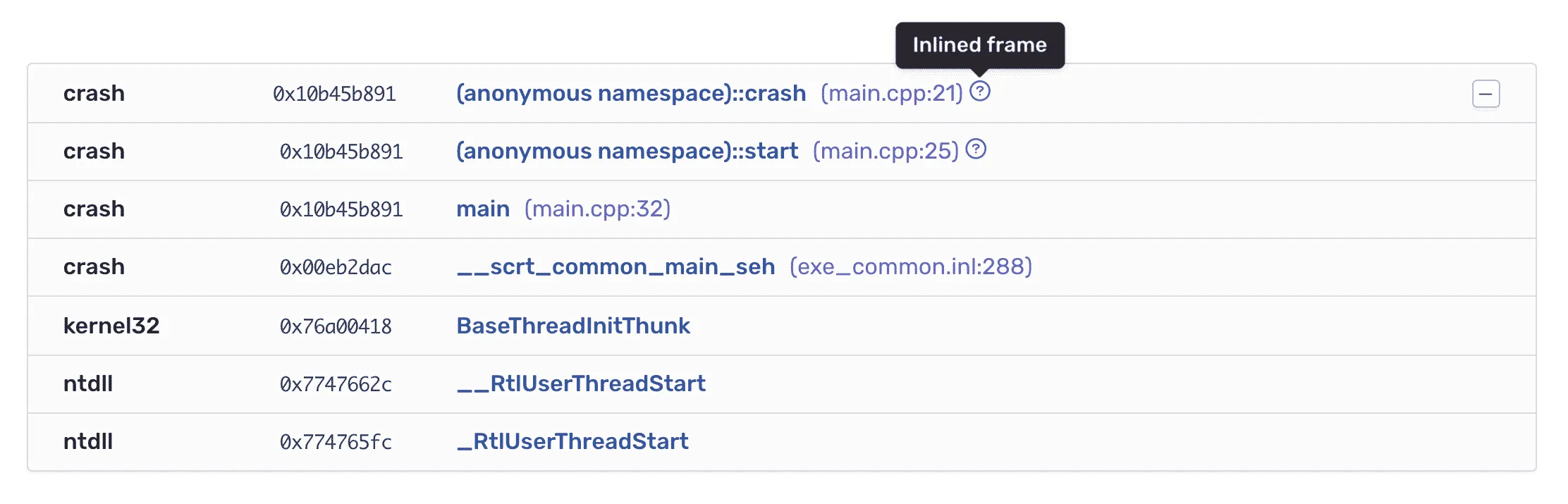
Of course, there are great Rust libraries that can handle debug information, including gimli for DWARF and pdb for CodeView, that are contributing to our improvements. In our own symbolic library, we’ve created a handy abstraction over the files and debug formats to simplify native symbolication.
Speeding it up
Dealing with large debug files also has its drawbacks. At Sentry’s scale, we’ve repeatedly run into cases where we were unsatisfied with the various aspects of retrieving, storing, and processing multiple gigabytes worth of debug information just for a single crash. Additionally, handling different file types all the time only complicates the overall symbolication process — even when hidden behind a fancy abstraction.
Engineers at Google faced the same issue when they created the Breakpad library. They came up with a human-readable and cross-platform representation for the absolutely necessary subset of debug information: Breakpad symbols. And it worked; those files are much smaller than the original files and can easily be handled by engineers.
However, their format is optimized for human readability, not automated processing. Also, certain debug information can’t be stored, such as inline function data, which is a core part of our product. So we decided to create our own format. The objectives: make it as small as possible and as fast as possible to read. And since it needed a name, we pragmatically dubbed it SymCache.
Usually, symcaches weigh an order of magnitude less than original debug files and come with a format that’s easily binary searchable by instruction address. Paired with memory mapping, this makes them the ideal format for quick symbolication. Whenever a native crash comes in, we quickly convert the original debug file into a SymCache and then use that for repeated symbolication.
Getting the right files
Ultimately, it is all about debug information. Debug information allows Sentry to extract stack traces from minidumps and symbolicate them into useful function names and more.
Because debug information is so vital, minidumps and iOS crash reports contain a list of all so-called images or modules that have been loaded by the process. Most importantly, this list includes the executable itself, but also dynamic libraries and parts of the operating system. Depending on the type, each module contains identifiers that can be used to locate them:
- Linux (ELF): On Linux, recent compilers emit a GNU build id, which is a variable-length hash. There are multiple strategies to compute this hash, from computing a checksum over the code to generating a random identifier. The build id is stored in a program header as well as a section of the file and usually retained when stripping debug information.
- macOS (MachO): The macOS executable format specifies a UUID in its header that uniquely identifies each build. The dSYM debug companion file matches the same UUID.
- Windows (PE, PDB): Microsoft’s PDBs specify a GUID and an additional age counter, that is incremented every time the file is processed or modified. Together with the file name of the PDB, they form the debug identifier triple. It is written into the PE header so that it can be located by just looking at the executable.
Sentry displays these identifiers on the Issue Details page and in the metadata of all debug information files. You can also use sentry-cli to inspect the identifier and other useful high-level information of your debug files locally:
$ sentry-cli difutil check MyApp.dSYM/Contents/Resources/DWARF/MyApp
Debug Info File Check
Type: dsym debug companion
Contained debug identifiers:
> 8fbdb750-4ea9-3950-a069-a7866238c169 (x86_64)
Contained debug information:
> symtab, debugDebuggers look for debug information files in various locations when they attach to a process. Search locations include the folder of the executable or library, paths specified in its meta information, or well-known conventional locations defined by the debugger. Sentry, of course, does not have access to those locations on our user’s machines, so we had to implement other mechanisms to retrieve these files.
Symbol servers
When we first introduced native crash handling at Sentry, we added the ability to upload debug information files for server-side symbolication. This can be done as part of the build process or CI pipeline to ensure that all relevant information is available to Sentry once crash reports are coming in.
With our newly announced support for symbol servers, we have now added a second, more convenient way to provide debug information. Instead of uploading, Sentry will download debug files as needed.
When implementing this feature, we realized just how inconsistent debug file handling still is. While Microsoft has established a de facto standard for addressing PDBs, all other platforms are still very underspecified. In total, we have implemented 5 different schemas for addressing debug information files on symbol servers:
- Microsoft SymbolServer (including compression)
- SSQP (Simple Symbol Query Protocol)
- Google Breakpad’s Directory Layout
- LLDB File Mapped UUID Directories
- GDB Build ID Method
While some of them are quite similar, they all handle certain file types differently or have their own formatting for the file identifiers. As we’re also continuing to expand our internal repositories of debug files, we will be working towards a more accessible and consistent standard that covers all major platforms to avoid issues like case insensitivity during lookup.
Symbolication as a service
Since the beginning, it has been our objective to create reusable components for the handling of debug information and native symbolication in general. For a long time, most of our efforts have concentrated on creating and contributing to Rust libraries. Aside from being a language predestined for a task like this, Rust’s ecosystem has been growing rapidly over the past years to provide an incredible set of tools for quick development in this space.
Over the past months, we have started to move a lot of the symbolication code that we have been using at Sentry into a standalone service. We’re now proud to present Symbolicator, a standalone native symbolication service. (Outstanding name, right?)
Symbolicator can process native stack traces and minidumps and will soon learn more crash report formats. It uses symbol servers to download debug files and cache them intelligently for fast symbolication. Symbolicator also comes with a scope isolation concept built-in so that it can be used in multi-tenant use cases. Over time, we will be adding more capabilities and tools around debug file handling.
Additionally, Symbolicator can act as a symbol server proxy. Its API is compatible with Microsoft’s symbol server, which means you can host your own instance and point Visual Studio to it. Symbolicator will automatically serve debug files from configured sources like S3, GCS or any other available symbol server.
Symbolicator is and will always be 100% open-source. For now, it can be built from source, and we will soon start to publish binary releases. Stop by, and feel free to open an issue in the issue tracker.