Sentry Points of Presence: How We Built a Distributed Ingestion Infrastructure
Event ingestion is one of the most mission-critical components at Sentry, so it’s only natural that we constantly strive to improve its scalability and efficiency. In this blog post, we want to share our journey of designing and building a distributed ingestion infrastructure—Sentry Points of Presence— that handles billions of events per day and helps thousands of organizations see what actually matters and solve critical issues quickly.
Space is Time
Historically (both before and after Sentry infrastructure migrated to Google Cloud Platform) all Sentry SaaS servers have been located in a single region somewhere in North America. This meant that users and servers transmitting events from the other side of the globe (e.g., Australia or India) were sometimes experiencing end-to-end latency as high as 1 second. Europe fared better (~450 ms,) but this still paled in comparison to events sent from within the continental US (a respectable ~150 ms.)
Ideally, Sentry SDKs should add as little overhead as possible, and that’s not feasible with a component in your app that regularly makes requests with 500-1000 ms of latency. Besides tying up system resources, on some platforms, this latency could have the seriously negative consequence of blocking all app execution (e.g., PHP, which is single-threaded and synchronous).
Additionally, after a request has been sent by the SDK, it has to make its way through the chaos of the public Internet, traversing wires we have no control over. And, after traveling all that distance, the event might be rejected or dropped because of exhausted quotas, invalid payload, inbound filters, or a number of other valid reasons. Which means the client application could wait for a full second just to learn the data was never ingested.
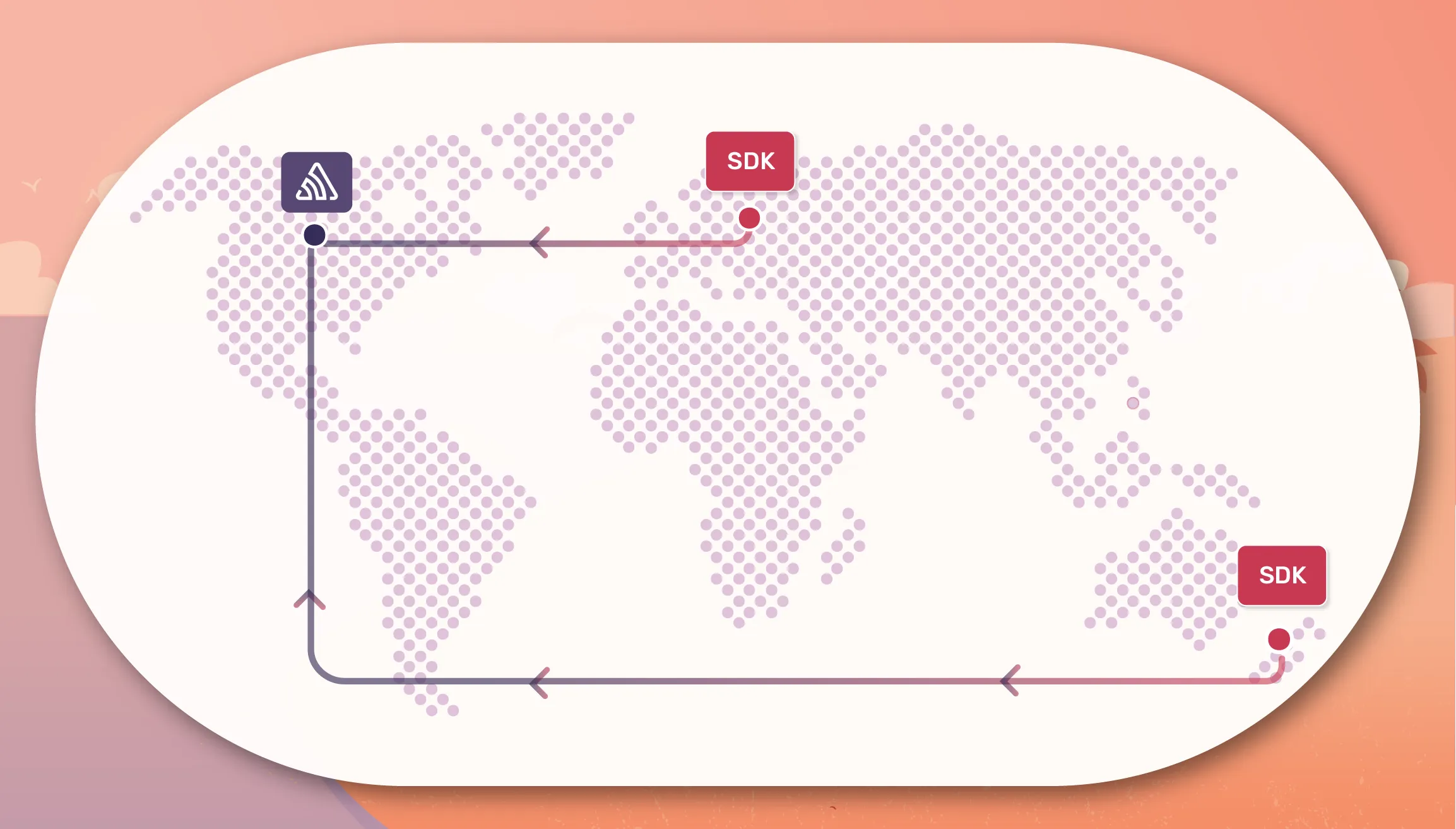
Sending an event with Points of Presence
Here are the most important components that shaped the final Points of Presence solution:
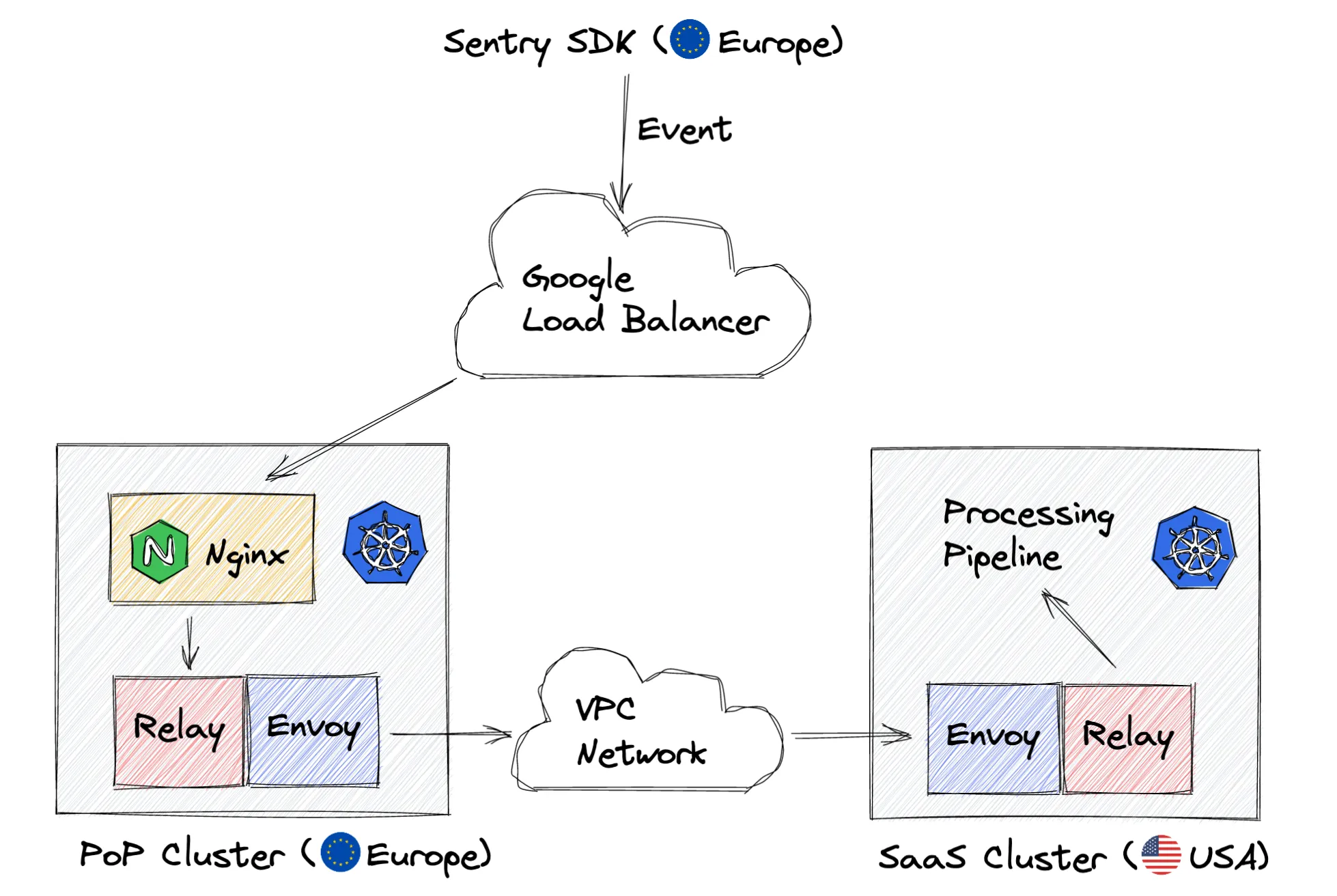
- Sentry Relay — Relay is a component that has been powering our ingestion infrastructure for more than a year, and throughout the PoP project, it had to learn how to wear a new hat. Relay is what ultimately allows us to reject invalid or above-the-quota events on the edge while sending all the good ones upstream to our main processing infrastructure. And most importantly, PoP Relay does the forwarding asynchronously from the user’s perspective, so SDKs do not have to wait for the event to reach our main infrastructure.
- Kubernetes — Container orchestration framework that lets us focus on “what” and not “how.” We already used Kubernetes for our main processing pipeline, so it was only natural to keep using it for our Points of Presence. Every Sentry PoP is basically a Kubernetes cluster in a separate geographic region that runs a few Relays and other auxiliary services such as abuse protection layer and logging agents. As Google Cloud Platform citizens, we naturally use Google Kubernetes Engine as a managed Kubernetes offering.
- Google HTTPS Load Balancer — A geo-distributed managed service provided by Google Cloud that allows us to hide multiple PoP clusters behind a single anycast IP address, also offering geo-aware routing to backends and efficient TLS termination. Additionally, after a user’s event reaches its closest entry point to the Google infrastructure, the data stays within the Google Cloud network—avoiding the turmoil of the public Internet.
- Nginx — Our favorite (but not only our favorite) web server. Nginx serves as a user-facing reverse proxy, powering our anti-abuse layer: if someone is sending us too many requests or if those requests are clearly invalid (invalid URL, payload too big, and so on,) Nginx will promptly respond with the corresponding status code.
- Envoy proxy — A powerful proxy software that connects different parts of our infrastructure and provides flexible instruments for cool things like service discovery, dynamic configuration, circuit breaking, and request retries.
When connected together, these components form the following architecture:
Showtime
The tricky thing about rolling out this exciting new infrastructure was that we had to preserve backward compatibility and keep supporting all the ingestion features and protocols we had in the product. And while lots of things can be checked and caught in development and testing, at some point, your infrastructure has to start handling production traffic.
Given the scope of the task, here’s what we did to prepare:
- We decided not to touch our main sentry.io ingestion hostname, and instead work towards enabling the PoP infrastructure only for organization subdomains, which were introduced in April 2020.
- We made sure that Relay could correctly operate in a special forwarding mode. In this mode, it becomes aware of the configuration state of the user projects, which in turn allows it to reject unwanted traffic efficiently, before it is sent upstream.
- Looking at how our users are distributed across the globe, we identified four initial regions to place our Points of Presence in North America, Europe, Asia, and Australia.
- At the end of October 2020, we announced that we’d soon be accepting events via an additional IP address. Many customers care about this sort of change (for example, because of potential changes to firewall rules), so we’re committed to communicating these changes in advance.
Now to the rollout itself:
- Phase 1: We started with selecting a few organizations that were sending us a lot of traffic via newly introduced organization subdomains and routed their traffic through PoPs. Not too difficult to do because it was just a DNS change on our side, specifically pointing a certain oXXXXX.ingest.sentry.io address to the new Google Load Balancer.
- Phase 2: We continued the rollout by enabling round-robin DNS for short periods of time when all user traffic was basically split 50-50 between the old and the new infrastructure.
- Phase 3: First attempts at temporarily enabling PoPs for all customer traffic. At this stage we had to deal with unexpected errors, troubleshooting, new discoveries, and additional work on stability. This was the time when almost all our initial design decisions were challenged by both organic and spontaneous increases in traffic, hard-to-reproduce issues, new product features that were released in the meantime, and missing tooling.
- Phase 4: Things were generally looking good, but with the learnings of the past months, we decided not to rush things. To avoid any unnecessary risks, we focused on improving monitoring, logging, and basically let the infrastructure do its thing at about 50% of the overall traffic for a couple months.
- Rollout Complete: In July 2021 Engineering Operations team routed 100% of relevant ingestion traffic to our new PoP infrastructure for the last time. At last, all metrics and graphs looked as they should have for more than just a few days straight, so we could officially call it a success.
Some challenges and lessons from the rollout included:
- Synchronizing idle timeouts between Envoy and Relay - Have you ever seen unexpected
50Xresponses from your reverse proxy servers with no obvious explanation? You might be a victim of inconsistent idle timeouts between your upstream and downstream applications. This is exactly the problem we hit at the initial stage of the rollout: an Envoy proxy located in front of Relay would occasionally return bad responses, even though there were no apparent issues with load or resources. After pinpointing the issue—which took embarrassingly longer than expected—and setting an Envoy idle timeout to a smaller value than the one in Relay, the issue went away. - Nginx and unexpected
CLOSE_WAITbehavior - In the middle of the rollout, we noticed that under sustained load, Nginx routinely kept an unexpectedly high number of sockets inCLOSE_WAITstate. It wasn’t causing any visible issues, but at the same time, it didn’t look normal, so we started an investigation and eventually managed to reproduce the issue in a local environment. A bug report followed, and thanks to the prompt response from the incredible Nginx team, the behavior was fixed in Nginx 1.19.9. - Logging pipeline challenges - Logging infrastructure is yet another thing that must scale (well) along with your system. Since we want to keep track of most of the requests in the anti-abuse level, we quickly realized that we need non-trivial modifications to the existing logging pipeline to be able to handle the entire user traffic. The first, naive solution to use Google Cloud Logging turned out to be more expensive and less flexible than expected, so we needed another approach. After reviewing a few potential options, we decided to build a new logging pipeline on top of Vector that allows us to efficiently buffer, transform, and then forward data to a centralized log storage.
What Success Looks Like
Unlike most of the product features we release at Sentry, our goal with deploying PoPs was to make it as frictionless and invisible as possible for our users—basically, just giving a free performance boost for most users without any required client-side changes.
With all the ups and downs of the lengthy rollout, the main questions that we had to answer were: what about all those numbers of milliseconds we were so unhappy about? Were all the troubles worth it?
Overall, the average response time around the globe dropped from ~500 ms to ~80 ms. And here are some examples of the response time changes for a few selected client locations:
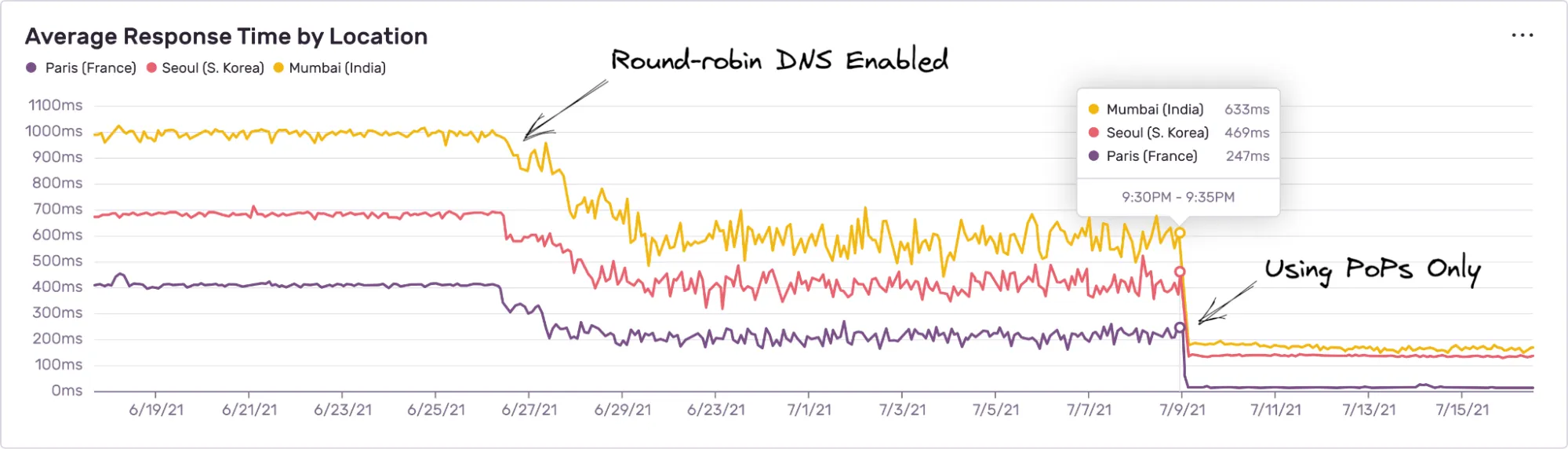
Requests from most European locations can now boast sub-100 ms response times, while the most remote locations (Asia, Australia) are within 100-200 ms now, depending on the proximity to the PoP regions.
Needless to say, it was truly an awesome feeling to see all those lines going down.
Are You Covered?
If you configured your Sentry SDK in the last 18 months or so, you most certainly already reap the benefits of the new ingestion infrastructure. However, some older clients might still be using legacy configuration that doesn’t utilize the full power of PoPs. To make sure that all your Sentry events are handled by the Points of Presence infrastructure, check whether you use an up-to-date DSN in your app.
Do you currently use a DSN that contains the legacy @sentry.io/ part? If so, please update your SDK configuration to use the current DSN from your project settings: go to Settings -> Projects -> Client Keys (DSN) in your Sentry account, and there you’ll find the up-to-date DSN value that will route your events through the closest Sentry PoP. The same recommendation applies also to the other types of client keys (for example, security header endpoint and minidump endpoint.) Their relevant values can be found on the same settings page.
Powered by Magic of Engineering
The PoP project was a joint collaboration between Ingest and Operations teams at Sentry, and we are very happy with the results. It was the first major step towards making Sentry infrastructure truly distributed and highly efficient—but it’s certainly not the last.
Would you like to be part of our next scaling project? We’re hiring for SRE and other roles across the company.