Formatting SQL in the Browser Using PEG
UPDATE: Our SQLish formatter is now available as a standalone package!
Sentry’s Performance team (a team I’m on, the team that works on features like Insights, Dashboards, Explore, and others) spent a big chunk of 2023 working on a database monitoring feature called “Queries”. “Queries” is a UI that shows information about SQL queries and their performance. SQL code is a central focus, so it became important to have good SQL formatting. None of the existing SQL formatters fit our needs, so we wrote our own! Our formatter has a few interesting features, so in this post I’ll explain what those features are, why they are interesting, and how we wrote our implementation.
Interesting Feature 1: Support for Invalid SQL
To format SQL, first you have to parse SQL. Many off-the-shelf SQL parsers are validating which means they will fail on SQL that isn’t valid. At Sentry, a lot of the SQL we display is very invalid. Here are a few examples of “SQL” we need to support:
SELECT * FROM users WHERE users.id = %s; /* Django ORM placeholders are not valid SQL! */
SELECT * FROM users WHERE users.ip_address = *; /* IP addresses are PII, and Relay strips them out */
SELECT * FROM users WHERE users.id IN (...) /* Long `IN` condition stripped out to reduce cardinality */
SELECT * FROM users WHER... /* Query was too long, we truncated the end */Our formatter successfully formats all kinds of invalid SQL-looking strings. For example, the string 'SELECT * FROM (SELECT * FROM use..' is not valid SQL, but is formatted as:
SELECT *
FROM (
SELECT *
FROM use..Aside: You can learn more about Relay in our documentation and if you’re curious about SQL parameterization, we have some documentation about that, too.
Interesting Feature 2: Support for JSX Output
I wanted our formatter to support multiple output types. I had an idea about gentle formatting done via bolding and italics, and I had some ambitions about interactive formatting (e.g., hovering on a table name in a query would show information about that table). Only some of those ambitions materialized, but to make them possible at all we needed a formatter that can output JSX nodes that we can attach styling to.
Our formatter supports two output types. The first output type is plain string, with spacing and indentation. This is well suited for displaying full queries, with line breaks, indentation, and syntax highlighting. Here’s an example of the UI it enables:

The second output type is an array of JSX elements, with <b> tags wrapping the important tokens. This is suitable for showing long, scannable lists of queries. Each query is shown on a single line, with just a hint of highlighting for the important tokens for readability. Here’s an example:
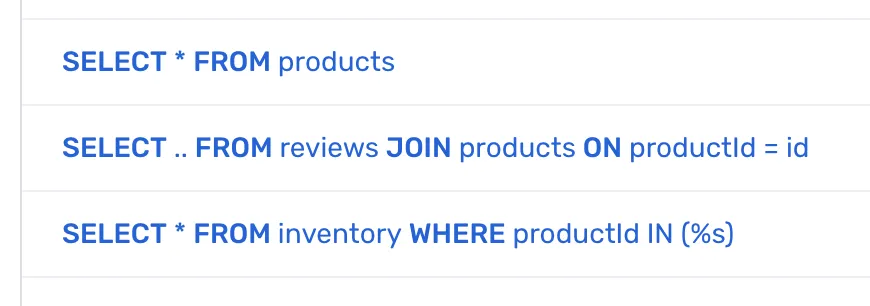
Fully highlighted strings wouldn’t make sense here. They’d take up multiple lines, they’be be overwhelming, and we want links to be blue, to indicate that they’re links.
Parse, Format
Let’s get into how this works, and why it does what it does. First, here’s an example of how to use the formatter:
const formatter = new SQLishFormatter();
const output = formatter.toString("SELECT hello FROM users ORDER BY name DESC LIMIT 1;");
console.log(output);
// SELECT hello
// FROM users
// ORDER BY name DESC
// LIMIT 1;Under-the-hood, there are two steps. The first is to parse the input string using a PEG parser (more on this soon) into a parse tree (more on this soon). The second is to take the parse tree and either format it as a string, or format it as JSX.
Parsing
A Gentle Introduction to Parsing
In order to transform a raw string of SQL to a rich output format, first one must parse the string. Parsing is usually done in two steps. The first step is to lexically analyze the string and split it into small chunks called “tokens”. The second is to take those tokens and construct a tree structure that describes the code in a way it could be transformed to bytecode and executed. This tree is called a “parse tree”.
For example, consider the query:
SELECT hello
FROM users
LIMIT 1;Tokenizing this would produce this array of strings:
["SELECT", " ", "hello", "\n", "FROM", " ", "users", "\n", "LIMIT", " ", "1", ";"];The key thing to notice is that it’s an array that contains all the characters from the input string.
Transforming it into a parse tree would create a structure that looks something like:
{
"type": "program",
"statements": [
{
"type": "select_stmt",
"clauses": [
{
"type": "select_clause",
"selectKw": {
"type": "keyword",
"text": "SELECT",
"name": "SELECT",
"range": [
0,
6
]
},
"options": [],
"columns": {
"type": "list_expr",
"items": [
{
"type": "column_ref",
"column": {
"type": "identifier",
"text": "hello",
"range": [
7,
12
]
},The key thing to notice is that it’s a deeply nested tree that accounts for the intricacies of SQL. Each token is given semantic structural meaning (is it a command? Is it a parameter?), its content (e.g. "SELECT"), its position in the original string (e.g., 7, 12) and other important metadata.
One way to accomplish this is to write a tokenizer that would split the string, and also write a parser that would create a tree structure from the tokens.
Another way to do this is to write a grammar. A grammar is a formal definition of a language, in a special syntax. The neat thing about grammars is that some grammars can be automatically converted to a parser! PEG is one such grammar. PEG parsers have some constraints and some known benefits that were acceptable to us, so that’s the route we took. Plus, we already use PEG in some other places in the app.
Aside: The tree above was made using https://astexplorer.net, a really great AST exploration tool.
Constructing a Grammar
If you’re wondering what a full SQL grammar looks like, you can find one on the internet. It’s a lot. We do not want a full SQL grammar. What we want is a grammar that’s aware of the basics of the language (keywords, operations, parameters, syntax markers). Our grammar cannot be aware of nesting, because a truncated query cannot be parsed, since the nesting might not be closed. Our grammar cannot be aware of hyper-specific syntax like casting, since it’s not supported in all SQL dialects. Our grammar must support very invalid characters like * in strange places. Therefore, our grammar (luckily for me) needs to be very simple.
Here’s an example of a very simple grammar for SQL, even simpler than the one we’re using in production:
Expression
= tokens:Token*
Token
= Whitespace / Keyword / Unknown
Keyword
= Keyword:("SELECT"i / "FROM"i) {
return { type: 'K', content: Keyword.toUpperCase() }
}
Whitespace
= Whitespace:[\n\t\r ]+ { return { type: 'W', content: Whitespace.join('') } }
Unknown
= GenericToken:[a-zA-Z0-9"'*;]+ { return { type: 'U', content: GenericToken.join('') } }The specific syntax might look foreign to you, but even at a glance you can see the basics:
- the grammar consists of a flat list of tokens, rather than a recursive definition
- each token can be whitespace, a “keyword”, or something unknown
- whitespace is one of several known whitespace characters
- a “keyword” is one of a few known SQL keywords
- “unknown” is a catch-all for other random characters
- the
.toUpperCase()and.join('')give you a hint of what is returned when parsing runs
If you’re curious what the resulting parser looks like, here’s a snippet:
function peg$parse(input, options) {
options = options !== undefined ? options : {};
var peg$FAILED = {};
var peg$source = options.grammarSource;
var peg$startRuleFunctions = { Expression: peg$parseExpression };
var peg$startRuleFunction = peg$parseExpression;
var peg$c0 = "select";
var peg$c1 = "from";
var peg$r0 = /^[\n\t\r ]/;
var peg$r1 = /^[a-zA-Z0-9"'*;]/;
var peg$e0 = peg$literalExpectation("SELECT", true);
var peg$e1 = peg$literalExpectation("FROM", true);
var peg$e2 = peg$classExpectation(["\n", "\t", "\r", " "], false, false);
var peg$e3 = peg$classExpectation([["a", "z"], ["A", "Z"], ["0", "9"], "\"", "'", "*", ";"], false, false);
...Aside: We run Peggy using Webpack. It compiles our .pegjs files to .js parser files.
You can see some some familiar tokens in the parser code, concepts we defined in the grammar.
This grammar knows about SELECT and FROM keywords, about whitespace, and a few other character. Here’s the tree it spits out for the SQL string SELECT * FRO:
[
{
type: "K",
content: "SELECT",
},
{
type: "W",
content: " ",
},
{
type: "U",
content: "*",
},
{
type: "W",
content: " ",
},
{
type: "U",
content: "FRO",
},
];You’ll notice a few things:
- The token
SELECTis recognized as type"K"(keyword) - The token
*is recognized as type"U"(unknown) but doesn’t cause the parser to fail - The output is a flat array with no nesting
If you’re thinking “this is just a tokenizer with extra steps” you’re not wrong. It’s not much of a tree. Maybe it’s a bamboo stalk. I don’t know, I’m not an arborist! In any case, so far so good. This is actually enough for simple queries. We could iterate this flat array, create <b> elements, or do whatever we want.
Improving a Grammar
The difference between this grammar and what we’re using in production is not huge:
- More keywords. Our full grammar supports about 30 common ones
- Parentheses. In order to know where to indent and add newlines, we want to know where parentheses are
- More special characters. Supporting all known ASCII characters (and even emoji, and other Unicode craziness) is important, so we need to extend what “unknown” is
- Complicated operations like
JOIN, so we can indent and highlight those - Special Sentry characters like
..
I won’t go into full detail, you can see the grammar on GitHub, but I’ll give you two highlights.
- The
CollapsedColumnstoken is a special string that denotes a long list of parameters, inserted by Relay. This is a Sentry-aware formatter, so it handles many Sentry-isms in the data:
CollapsedColumns
= ".." { return { type: 'CollapsedColumns', content: '..' } }GenericTokenis a catch-all for pretty much all known characters in the entire Unicode BMP including surrogate pairs and unassigned code points. Talking about Unicode is so far outside the scope of this post I don’t even want to touch it:
GenericToken
= GenericToken:[a-zA-Z0-9\u00A0-\uFFFF"'`_\-.=><:,*;!\[\]?$%|/\\@#&~^+{}]+ { return { type: 'GenericToken', content: GenericToken.join('') } }Combining enough of these expressions makes it possible to parse just about anything.
Formatting as a String
String formatting needs to do four main things.
- Create newlines for important keywords
- Increase indentation for some parentheses
- Wrap the code at a reasonable length
- Syntax highlighting
Turns out, it’s pretty simple to do those things with simple heuristics! By checking the current token, the preceding token, the current indentation level, and the current nesting level, we can handle very sophisticated queries.
The pseudocode for formatting is pretty simple. Go token-by-token. An open parenthesis increases the indentation level. A meaningful keyword (e.g., SELECT) creates a newline. A closed parenthesis decreases the indentation level. After initial formatting, go through the formatted lines, and wrap them if needed. There are many edge cases to cover, but that’s the gist! You can see the full code on GitHub.
The last piece is syntax highlighting. We have enough information to do this ourselves (we know which strings are important keywords), but there’s no need. Prism is a very popular open-source non-validating syntax highlighter that suits our needs just fine. That’s it!
A reminder of what the output looks like:
Formatting as JSX
JSX formatting is even simpler. It’s very simple. Go token-by-token. If the token is known to be a keyword, return it wrapped in <b>. If it’s whitespace, return a single space. If it’s something else, return it wrapped in a <span>. That’s the whole formatter. Then we can use CSS to style the output however we like, add click handlers, and so on. Here’s the same screenshot as above as a reminder of the output format:
You can see the full code, again, on GitHub
Telemetry
Everyone at Sentry is low-key obsessed with gathering telemetry. Me too! Before I could ship this to everyone, I had to answer two important questions. The first is, how often are we failing to parse a query? The second is, how fast does this formatter run?
How Often
Remember the GenericToken piece of the grammar? That was hard-fought. I could have allowed literally every character right off the bat, but I wanted to learn. I started slowly rolling out the new formatter, and would throw an exception every time the parser failed. The parser degrades very gracefully to an unformatted but still syntax-highlighted string. Every time I saw an exception, I would figure out what syntax I missed, and add a test case for it.
try {
tokens = this.parser.parse(sql);
} catch (error) {
Sentry.withScope((scope) => {
scope.setFingerprint(["sqlish-parse-error"]);
// Get the last 100 characters of the error message
scope.setExtra("message", error.message?.slice(-100));
scope.setExtra("found", error.found);
Sentry.captureException(error);
});
// If we fail to parse the SQL, return the original string
return sql;
}The result is a list of specific, descriptive test cases that explain why certain characters are part of the set, and what they mean:
'AND created >= :c1', // PHP-Style I
'LIMIT $2', // PHP-style II
'created >= %s', // Python-style
'created >= $1', // Rails-style
'@@ to_tsquery', // Postgres full-text search
'FROM temp{%s}', // Relay integer stripping
'+ %s as count', // Arithmetic I
'- %s as count', // Arithmetic II
...I kept going until GenericToken had everything we saw in the wild, and the issue stopped appearing.
How Fast
The second question is, is this parser fast enough to run in production? I manually instrumented Sentry spans for the formatter, so I could track how long formatting actually takes on real users’ computers. Benchmarks are nice, but contact with reality is brutal and I’d rather learn from reality right away.
const sentrySpan = Sentry.startInactiveSpan({
op: 'function',
name: 'SQLishFormatter.toFormat',
attributes: {
format,
},
onlyIfParent: true,
});
...
sentrySpan?.end();The first set of measurements was:
- p75 is 0.2ms (very fast!)
- p95 is 6.0s (hmm)
Not amazing results at the 95th percentile, but this was before any optimizations (I added some later) and the browser environment is so volatile, some wild outliers will always show up. I was comfortable with this as a starting point, especially since spot-checking long queries looked good, and because parsing only happens one per page load, and our main source of user-perceived slowness is data loading anyway.
I checked the data today, and here’s what I saw:
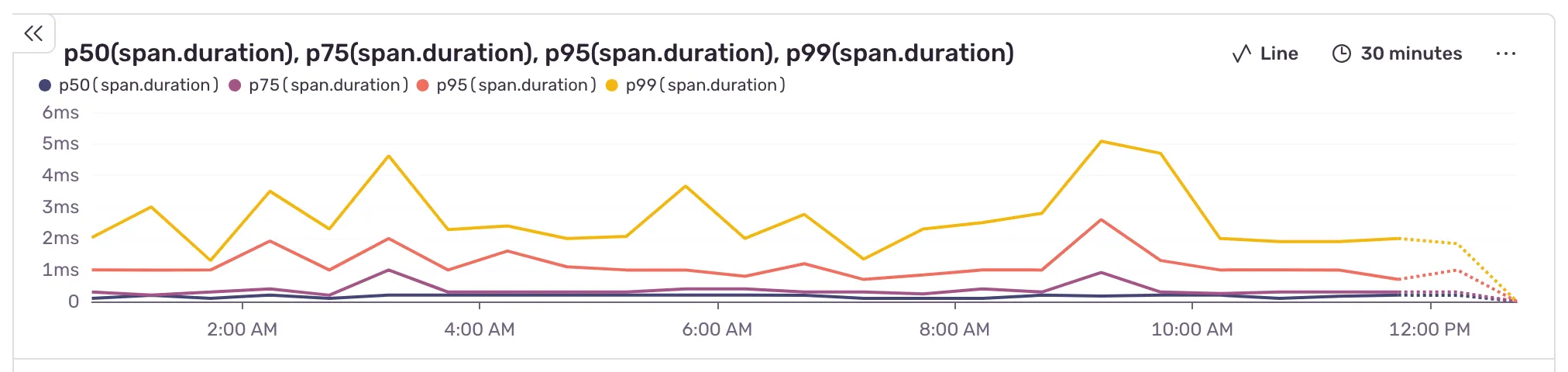
Not bad!
Aside: If words like “p95” don’t mean anything to you, Wikipedia has a thorough explainer on percentiles.
Conclusion
If you’re using Sentry’s “Queries” feature, and you’re looking at formatted queries, you’re looking at the output of this formatter. I read online somewhere that once you understand parsers, you start to see everything as a parsing problem. After this project, I’m starting to agree.
Resources
Here are some resources I used when I was working on this project:
- The Super Tiny Compiler is a beautiful project on Glitch. It’s a fully annotated and deeply explained simple compiler
- Wikipedia’s entry on PEG was an obvious first choice, and it even has resources on esoteric topics like removing left recursion
- A Text Pattern-Matching Tool based on Parsing Expression Grammars is a really interesting (but dense) paper. I must have read something in it that I liked, but now it was so long ago I don’t remember what it was
- Guido van Rossum has a series about PEG on Medium that was paywalled at the time, but seemed promising
- This medium post about PEG and Lua/SQL was interesting and helpful, though I ended up going in a different direction
- pegedit was recommended online as a resource for tinkering with PEG, but I mostly used Peggy’s own playground
I also found a bunch of lectures on PEG grammars online from—I think—Princeton, but now I can’t find them. Sorry!