How open PR comments work
At Sentry, we always want to bring value to the developer. One area we can do this is through developer workflows, such as pull requests. If you’re already working in a particular area, it’s useful to be informed about issues related to the code you’re changing so you can be proactive in acknowledging and addressing them.
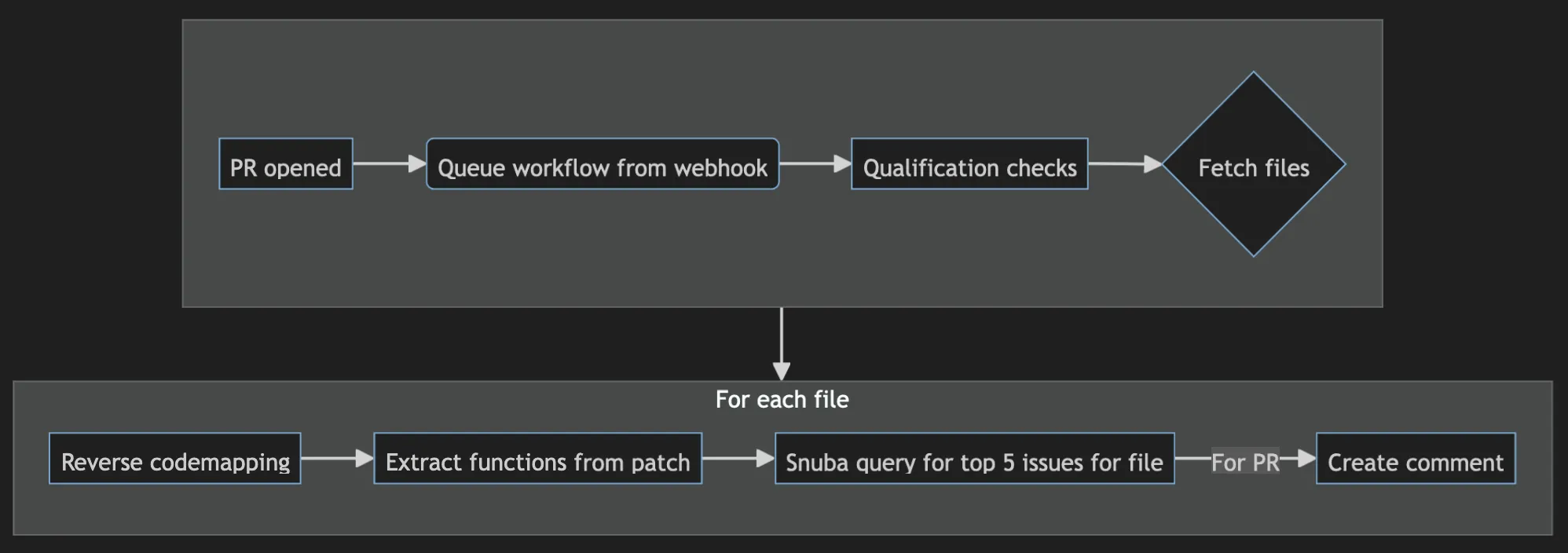
When somebody opens a GitHub PR, we parse the functions from the PR diff, search for unresolved, unhandled issues related to those functions in the PR files, and make a nice little comment on that PR.
How it works
Webhook
When somebody installs the Sentry GitHub App, we request permissions so that we can consume webhooks for particular events that we would like to handle. We have a webhook for pull request events that does stuff on the Sentry side when somebody interacts with a pull request on GitHub. So when somebody opens a pull request, we can kick off the open PR comment workflow.
Comment workflow
Qualification checks
We fetch information for the PR files from GitHub, and then ensure that we don’t comment on PRs that have any of the following:
- More than 7 files modified
- More than 500 lines changed
We also don’t count files that are:
- Deleted, because we cannot extract function information due to the GitHub API does not giving us a patch
- New, since they won’t have any issues associated with them
Why do we do this? At a certain point, when a PR is touching so many lines and/or files, it becomes less and less useful to point out specific issues related to the functions inside the PR. For instance, if somebody applies a linting change, it could result in a lot of lines modified.
Note that we only support a particular set of languages (via looking at file extensions). We skip counting files and lines if they don’t have a file extension we support, and only continue with the files that we can support if these checks are met.
Fetching issues for each file
Reverse codemapping
- Normal codemappings map a file in the stack trace (within Sentry) to the source code (in a source code management integration such as GitHub) using a stack trace root and a source code root. Sentry may store file names differently than in GitHub, so codemappings store this relationship. We leverage codemappings here because we want to figure out the Sentry project(s) associated with the file and the stored name of the file in order to make a Snuba query, which requires
project_id. - We use the organization, the repository, and the file name to attempt to fetch code mappings for the file, matching on whether any source code root for a codemapping is a substring of the file name. If any codemappings are found, we reverse codemap by replacing the source code root in the file name from GitHub with the stack trace root. (Reverse because usually we go from stack trace to source code root, for instance when opening up a line from a stack trace in GitHub)
Extract functions from the file patch
- Depending on the language of the file, we fetch the appropriate parser and apply it to the file patch (the
git difffor the file). - This applies a regex to the whole file, looking for git hunk headers (e.g.
@@ -188,9 +188,7 @@ def __init__():for Python) that indicate a function in the language, and that the code modified in the section below it belongs to that function. This is more or less correct in finding functions being modified in a PR, unless the function is super short or the lines modified are near the top of the function (this is a limitation of git). - For Python, the regex only looks for
def {function_name}.For JavaScript/TypeScript, there are more ways to initialize a function (function declaration, arrow function, function expression, etc), so there are multiple regexes to find function names.
Snuba query to fetch top 5 issues by count
- We first fetch the first 10k unresolved issues for the projects found via reverse codemapping through Postgres, ordered by times seen. This is to prevent overloading the Snuba query if we pass in too many issue ids.
- Next, we have a complicated looking Snuba query that does the following:
- Subquery to fetch the count of events for each issue id
- Query that filters on the subquery to 1) squash issue ids with the same title and culprit, 2) look for unhandled events that have the file name+function combo for any of the file’s function within the first 4 frames of the stacktrace, and 3) return the top 5 issues with the greatest count of events
- There is also some different logic being inserted depending on the language of the file. For instance, for JavaScript/TypeScript we also look for events that have
{any classname}.function_nameinside the file in addition to justfunction_nameinside the file because of how JavaScript/TypeScript events are stored.
Create comment
Then for each file, we make a little table with the function and issue information. All the tables besides the one for the first file are hidden in a toggle. Each file type may also have a slightly different formatting template. In JavaScript/TypeScript, we want to show the Affected Users because it’s more important for frontend. Meanwhile, Python usually always has 0 affected users so it’s not shown.
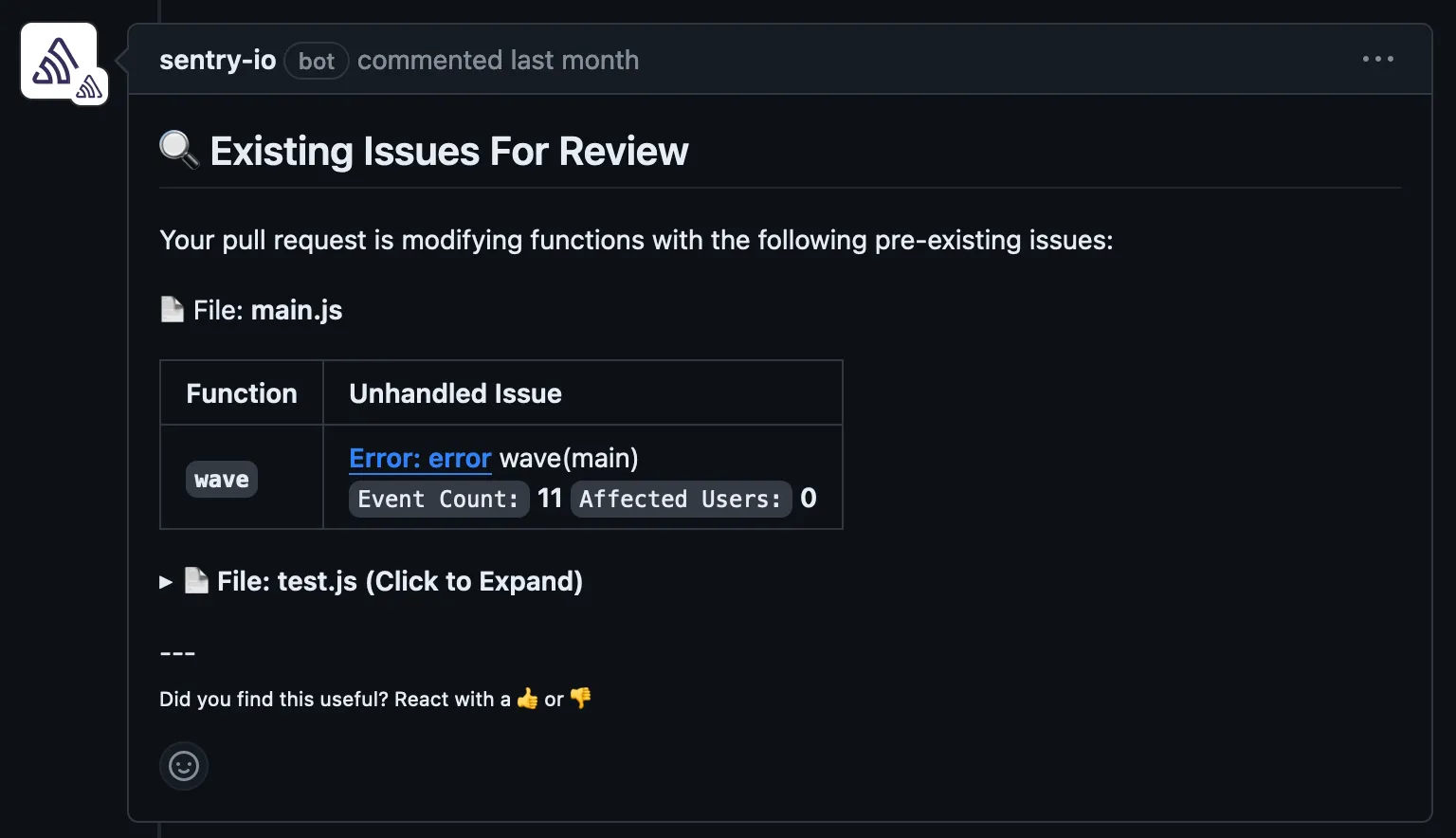
A note on language parsers
We support different languages in open PR comments. However, they also require different methods to extract functions from the diff, different handling for the ways events with those functions might be stored in Snuba, and how to format the comment table for each file type. The current list of support languages can be found in our docs.
Each file extension that we support is mapped to a language parser.
If we find more things that are different between languages, we can add to the parser classes. So far we have:
- Issue row template for the comment
- Extracting functions from patch
- multiIf
- This can contain custom logic to fetch the function name from the stackframe that matches the file name + a name within the list of function names.
- We do this because we can match up to X frames deep in the stacktrace, we might have a set of function names we’re matching on, and we want the actual function name that we matched on in the stack trace. The stack trace is stored as an array.
Example language parser
Language parser base class (code)
Example implementation for JavaScript (code)
How we got here
I also wanted to call out that getting here was no easy feat. We also investigated using abstract syntax trees (ASTs) to be completely sure what functions had been modified. However, the tradeoff would be that we would need to 1) hit more GitHub APIs to fetch the complete files and the files for the base commit for the PR and 2) construct or borrow AST logic for each language to make the comparison.
We decided to iterate from the simplest implementation possible in case it became apparent that the project was not worth pursuing. we first iterated internally with only file-level granularity for these open PR comments. This was not received well, so we knew that we needed to implement open PR comments with function-level granularity.
How do I get these?
If your project is written in a language that we currently support, and you use GitHub, navigate to the GitHub integration features and toggle Enable Comments on Open Pull Requests!
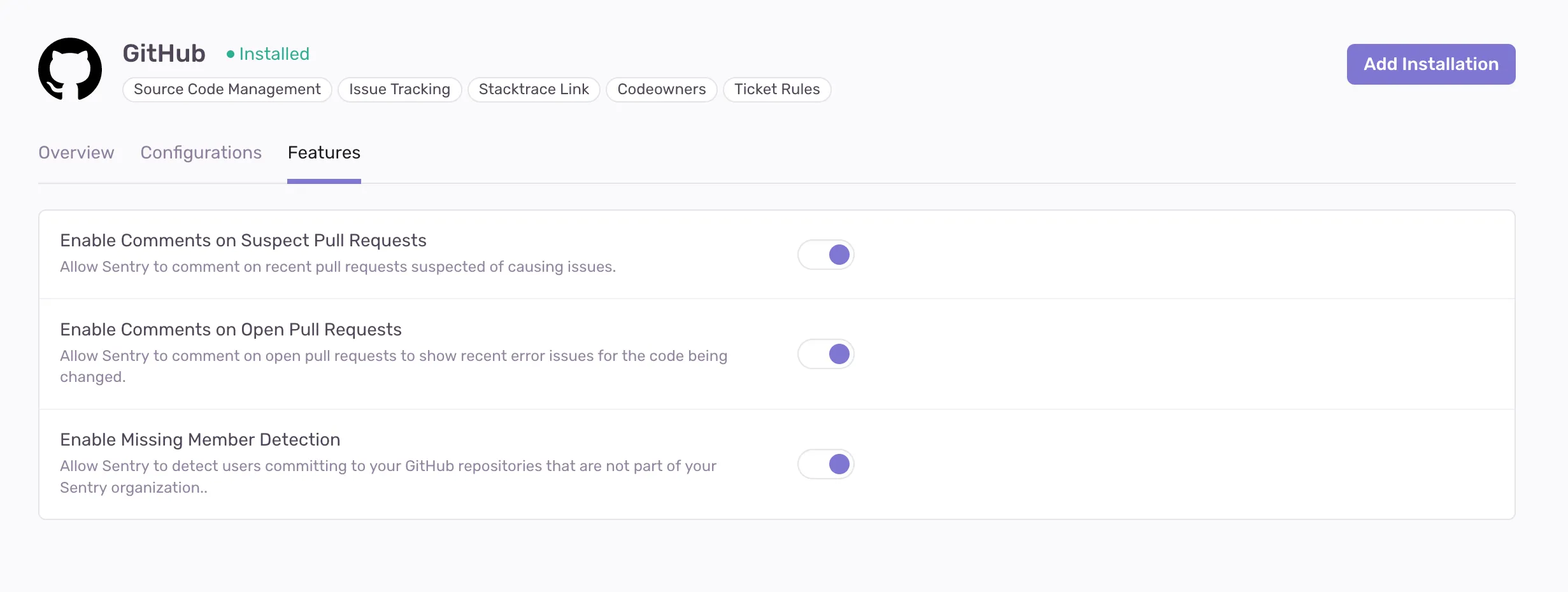
Open PR Comments is currently only available on GitHub, and we are looking to extend all the PR comment features to other SCM integrations soon (GitLab, Bitbucket, etc). For more feature requests, submit an issue to the Sentry repo or comment on the PR comment GitHub discussion https://github.com/getsentry/sentry/discussions/49996