Removing risk from our multi-region design with simulations
In case you’ve missed it Sentry now offers data residency in the EU alongside our US data residency. When we first embarked on designing what a multi-region experience for Sentry would look like we had a few goals and requirements in mind:
- While our immediate need was to offer data residency in the EU. The same model should be re-usable for future regions.
- We didn’t want to compromise on the product experience. Customers shouldn’t have to manage multiple login accounts, or remember what region their data was in.
- Customers installing integrations with 3rd parties shouldn’t have to deal with matching the integration and their region.
- We needed to maintain backwards compatibility for all existing customer API usage and ingestion.
- Our design would need to scale down for self-hosted and local development.
High level design
Adding an EU region as a peer to the US region meant that our application architecture would be moving from this design:
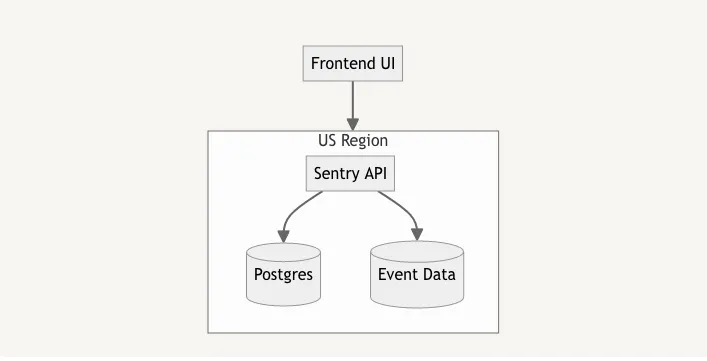
to one that looks like:
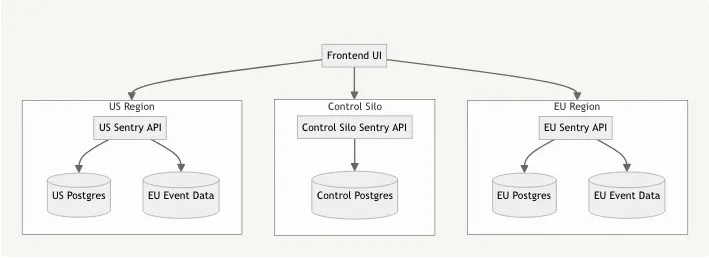
This second diagram has some significant changes. Beyond the expected separation of the US and EU regions is the introduction of a ‘Control Silo’ which includes a dedicated postgres cluster, and other storage services not depicted.
What are silos?
The names ‘Control Silo’ and ‘Region Silo’ came from the need for a clear and concise term that didn’t overlap with common cloud computing concepts like regions and zones. Within Sentry most data belongs to Organizations. However, we also have data that is shared by multiple organizations, and data that is required to be unique globally. Shared resources include concepts like User and Integrations. Organization slugs are an example of data that must be unique across all regions.
In our future state, application instances would be deployed in a single silo mode - either control or region. Additionally a third silo mode known as monolith mode is used to represent the state where silo modes are not enforced, or the application is run without regions enabled. Region Silos are isolated, and cannot communicate with each other. Regions can access data that lives in control via cross-region remote-procedure-calls (RPC). Beyond housing resources shared between regions, Control Silo also provides backwards compatibility for existing API clients. We’ll cover how we’ve designed Integrations and API compatibility for multi-region Sentry in a future post.
Finding the boundaries
Splitting our application into two new operational modes (control and region) would require many changes to separate our data model and task dispatching along the silo boundaries. While we had rough ideas of where the silo boundaries should be, Sentry is a reasonably large and complex application and we weren’t confident that we had covered all scenarios. Before making any permanent changes to our postgres databases we wanted to have a high degree of confidence in our decisions, and ability to preserve the application’s behavior with the database and application logic split.
Simulating the boundaries
We knew that we were going to have many code paths that crossed the silo boundaries as User was going to be a Control Silo model, while many resources that reference User would be in the Region Silos. What we didn’t know was the impact of splitting the database up.
We decided to sketch out silo boundaries with runtime metadata before making any permanent changes. Our prototype of silo boundaries would let us answer a few questions:
- Did we get any silo assignments wrong?
- How much of the application is going to have to change?
- Where will we need to make changes?
We chose to implement silo metadata using python annotations.
from django.contrib.auth.models import AbstractBaseUser
from sentry.db.models import BaseModel, control_silo_model
@control_silo_model
class User(BaseModel, AbstractBaseUser):
...By annotating Django models we could add metadata, and build tooling that uses the generated metadata to identify foreign keys that were spanning models in opposing silo modes. These foreign keys would need to be broken, and have their cascade operations replicated in application code. Model annotations also served as the foundation for generating a rough first pass at assigning silo modes to endpoints and tests.
With the silo boundaries roughed in, we made the application aware of silo modes during runtime and expanded the functionality of our decorators. Our next step was to monkeypatch Django’s ORM to raise errors when cross silo operations are performed. For example, if the application uses User.objects.filter() while in region mode we should get an error:
Traceback (most recent call last):
# Prior frames elided for brevity
File "/Users/markstory/code/sentry/src/sentry/api/endpoints/organization_member/index.py", line 119, in validate_email
users = User.objects.filter(email=email)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/markstory/code/sentry/.venv/lib/python3.11/site-packages/django/db/models/manager.py", line 87, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^
File "/Users/markstory/code/sentry/src/sentry/silo/base.py", line 153, in override
return handler(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/markstory/code/sentry/src/sentry/db/models/base.py", line 409, in handle
raise self.AvailabilityError(message)
sentry.silo.base.SiloLimit.AvailabilityError: Called `get_queryset` on server in REGION mode. The model is available only in: MONOLITH, CONTROLHaving these errors in our CI builds and pre-production testing let us pinpoint code paths that would need to be updated. Enforcing silo boundaries was toggled by annotations on test cases, giving us a way to incrementally improve the application without disrupting other teams.
Applying silo annotations to models, and endpoints got us pretty far into understanding the scope of work that would be required, and the impact splitting our database would have. We were also able to gain enough confidence on the resource assignments to start prototyping what it would take to make the application ‘silo stable’.
Working towards Silo stable tests
With our models, endpoints, tasks and tests annotated with a first pass of silo mode annotations we started to prototype what a ‘silo stable’ state looks like for an initial set of endpoints. We incrementally updated tests to run in ‘silo stable’ mode.
from sentry.testutils.silo import control_silo_test
@control_silo_test(stable=True)
class UserDetailsTest(TestCase):
...When stable=True was enabled for a test, we would run the test twice. Once in ‘monolith’ mode, and again in the assigned silo mode. This let us have confidence that the application would behave correctly in both its current operation mode (monolith mode) and in the future state (separated by silo modes), and it prevented regressions from being introduced by other changes.
Getting 35,000 tests passing in silo stable mode was a slow process that involved:
- Identifying code paths that relied on foreign keys spanning silo modes. This could be done by temporarily enabling
stable=Trueand seeing what tests failed. - Each problematic code path would need to have cross-silo queries replaced with RPC service calls. In tests, these service calls simulate crossing silo boundaries by mutating the active silo state to round out our simulation.
- With tests passing,
stable=Truewould be enabled by default.
Running all tests twice added strain to our CI systems as towards the end of our work we were running most tests twice to ensure silo mode isolation. Once we had completed silo stability across all tests, we were able to make stable=True the default and remove double execution of tests for all but a select few scenarios.
What worked well and what didn’t
Using our CI suite to validate the future state of the application was an invaluable tool while we developed Sentry’s multi-region offering. Using annotations to simulate the future state gave us a powerful toolbox to reshape the application and continuously integrate our work without disrupting other teams or introducing regressions in tested code paths. The downside of this approach was that many teams lacked context on what the annotations were for and how they were assigned. Monkeypatching Django’s ORM meant that our changes were in many stacktraces confusing both our automatic issue triaging rules and developers alike.
In the later stages of this project, during end-to-end testing in a pre-production environment we identified many silo boundary errors that we didn’t catch with tests due to a lack of coverage. Like many teams Sentry doesn’t have perfect test coverage and even where we do have line coverage we don’t always have full branch coverage. Thankfully, none of the silo boundary issues we missed were show stoppers that required tables to move between silo modes.
With a lot of small incremental changes we were able reach the milestone of having 100% of tests passing with silo stability enabled. With tests fully passing we had built enough confidence to finalize the silo assignments and begin the physical database split. We’ll cover that more in a future post though.