How we fixed incorrect Codecov bundle size reporting
What is Bundle Analysis?
Bundle analysis is a new product offering from Codecov. This product consists of a set of bundler plugins that users can choose from for their specific bundler or meta-framework. Once a plugin is installed and configured in the respective configuration file, the plugins will run when the application is being bundled. During the bundling process the plugins will collect and organize the assets, chunks, and modules for your bundle into a stats file and upload these stats to Codecov. With these stats we enable developers to gain insights into their JavaScript bundles, such as overall bundle size, problematic assets, etc. Bundle analysis relies heavily on your Git workflows similar to any other Codecov product. We closely replicate your Git tree to give you insights at major points in the development lifecycle such as commits and pull requests.
How Codecov Follows Along with your Git Flows
To replicate your Git tree when bundle reports are uploaded to Codecov they are sent along with the corresponding commit SHA so we can create the commit and grab more details about it from GitHub such as the parent commit, the author, commit message, etc. Typically we end up creating commits in Codecov after users have opened a PR and ran their CI. Which at the same time as opening your pull request Codecov receives a webhook from GitHub and will create a pull request entry in our database storing the relevant information such as the base and head commit SHAs.
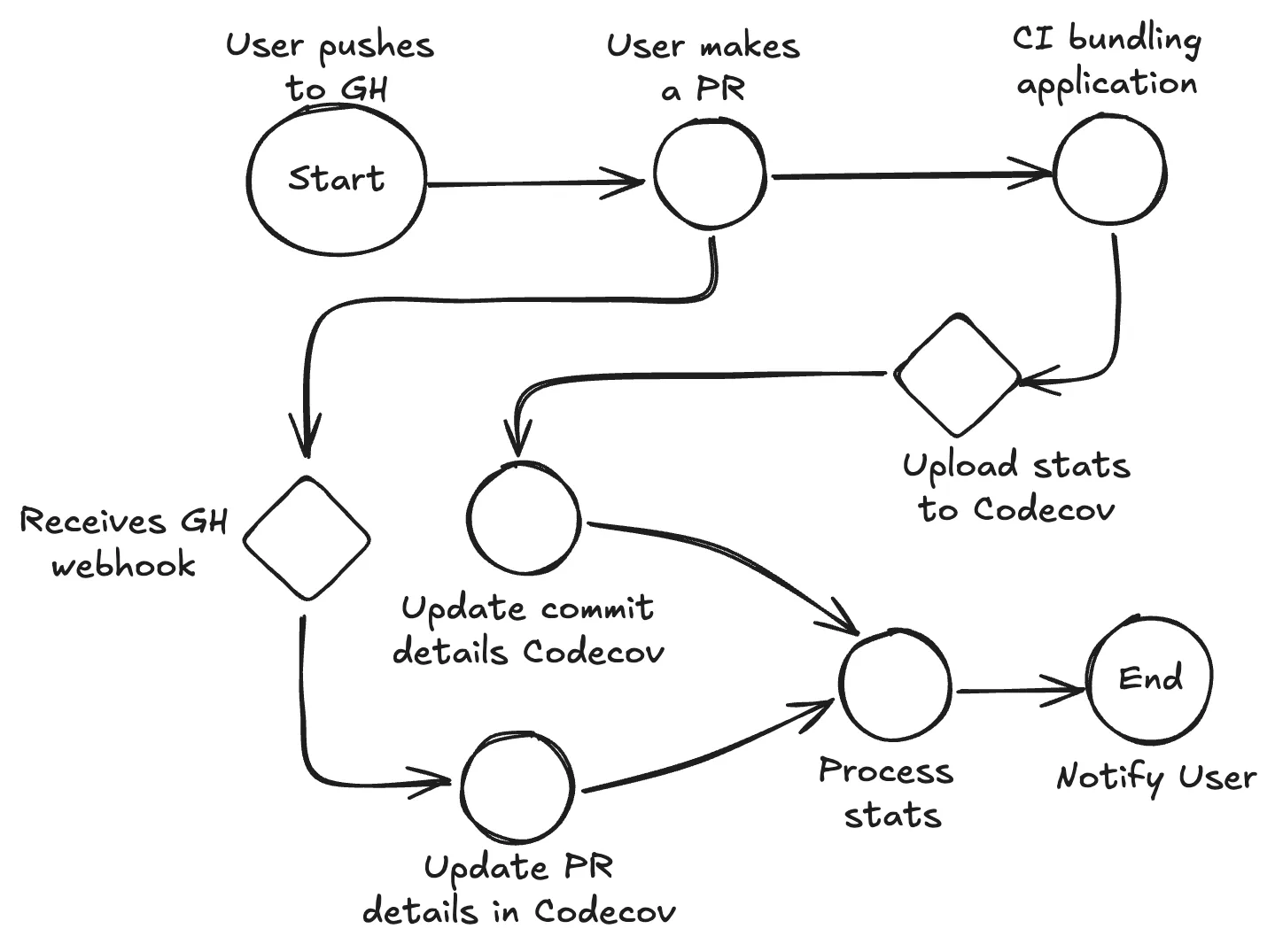
Your repository often contains information that is unrelated to tests and JavaScript bundles like CI configuration or documentation. All this info requires commits to be updated properly within your repository. Typically these changes will result in your CI not running and in turn not running your tests or building your bundle and sending a report to Codecov. So, how can we compare the difference between commits and give you the correct information when a parent commit doesn’t exist in Codecov? To accomplish this, we will “walk” up the Git branch until we find a parent commit that has a valid report to compare against and store that information in our pull request entry. This enables us to correctly compare the information between your latest changes and the most recent reports that were uploaded to Codecov.
In typical CI environments this works pretty well, as they expose the correct Git information (typically) as environment variables, which we grab inside the bundler plugins while they’re executing and pass along with the bundle stats information. However, when running GitHub Action workflows you’re required to run actions/checkout. This action uses Git to copy your repository into the action runner, however during the steps of this action it creates a merge commit between the head commit of your feature branch and the head commit of the branch you’re looking to merge to. A problem arises when running this action and trying to get the correct commit SHAs. Because the action creates this new merge commit it creates a detached commit that does not belong to any branch, and its “parent” commit is not the same as your feature branches head commit
This is an action that checks out your repository onto the runner, allowing you to run scripts or other actions against your code (such as build and test tools). You should use the checkout action any time your workflow will use the repository’s code. ~ GitHub Docs
Base and Head Commit SHA Issues with GitHub Actions
Here on line 73 you can see highlighted in the image this checkout to the merge-commit occurring:
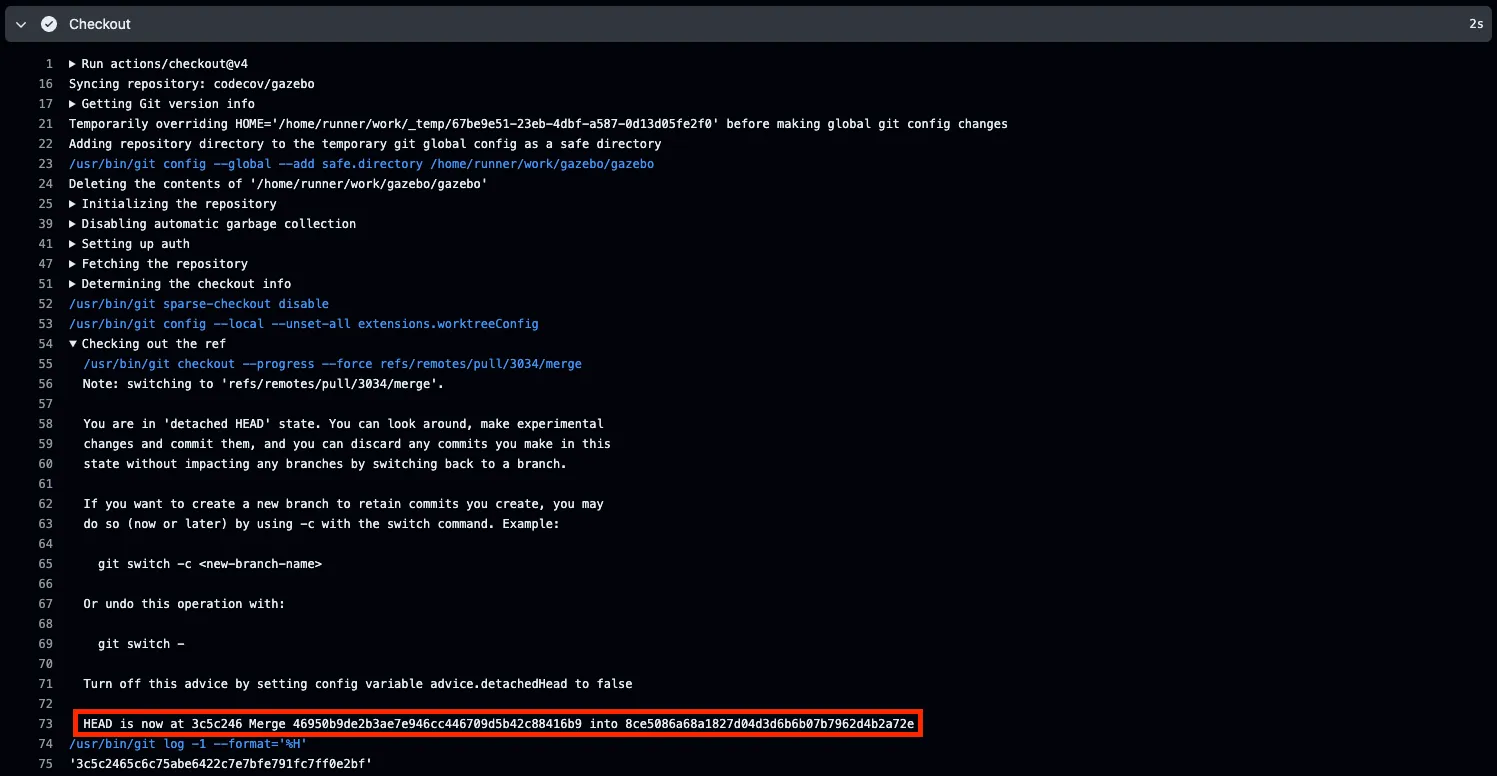
HEAD is now at 3c5c246 Merge 46950b9de2b3ae7e946cc446709d5b42c88416b9 into 8ce5086a68a1827d04d3d6b6b07b7962d4b2a72eThis flow creates a two big problems for Codecov when we try and determine the correct commit SHA. This new commit that is being created does not belong to any branch inside the repository, which is a limitation for Codecov as we expect commits to belong to a valid branch and to have a single parent rather than two. Secondly, this commit takes the head of your branch and merges it with the head of the comparison branch, not the commit that you originally branched off of. This results in an incorrect comparison because there are changes in the branch you’re merging into that do not appear in the base commit for your branch.
Solving Incorrect Head Commit SHA’s
Let’s tackle the first problem that arises here, the creation of a new commit SHA. When this action happens it sets the GITHUB_SHA to this new detached commit SHA. Because this commit only exists in this detached state it doesn’t have any useful information to it and we don’t want to use it to create the commit inside of Codecov. To address this issue in the bundler plugins, we utilize the @actions/github package, this enables us to grab details from the GitHub Action context payload. We first need to check and see if the action is running in a pull request. We can do this by checking the context event name to see if it matches that of a pull request. Now that we know we’re running in a pull request, we can grab the pull request details from the context payload which includes information about the head commit and the correct SHA.
import * as GitHub from "@actions/github";
// ...
function findCommitSHA() {
let commit = envs?.GITHUB_SHA;
const context = GitHub.context;
if (["pull_request", " pull_request_target"].includes(context.eventName)) {
const payload = context.payload as PullRequestEvent;
commit = payload.pull_request.head.sha;
}
return commit;
}We have tackled the issue of avoiding the creation of detached commits in Codecov, and can associate the correct bundle stats information with the commit where the changes were made. A new problem now arises in repositories that have a large number of contributors, making large amounts of commits to your default branch, in turn moving quickly. With these fast moving repositories, PRs that are opened have their changes compared to the latest commit on the branch being merged into instead of your branches base commit.
A Second Problem Arises
The second problem that occurs is one that’s a little more confusing to get your head around, and it took us some time to figure out what was actually going on. During the action, it checkouts to a new commit that is based off of your branch head commit and the current head commit of the comparison branch. To better explain the entire process that happens here is a graphic showing what is actually going on through-out the entire process:
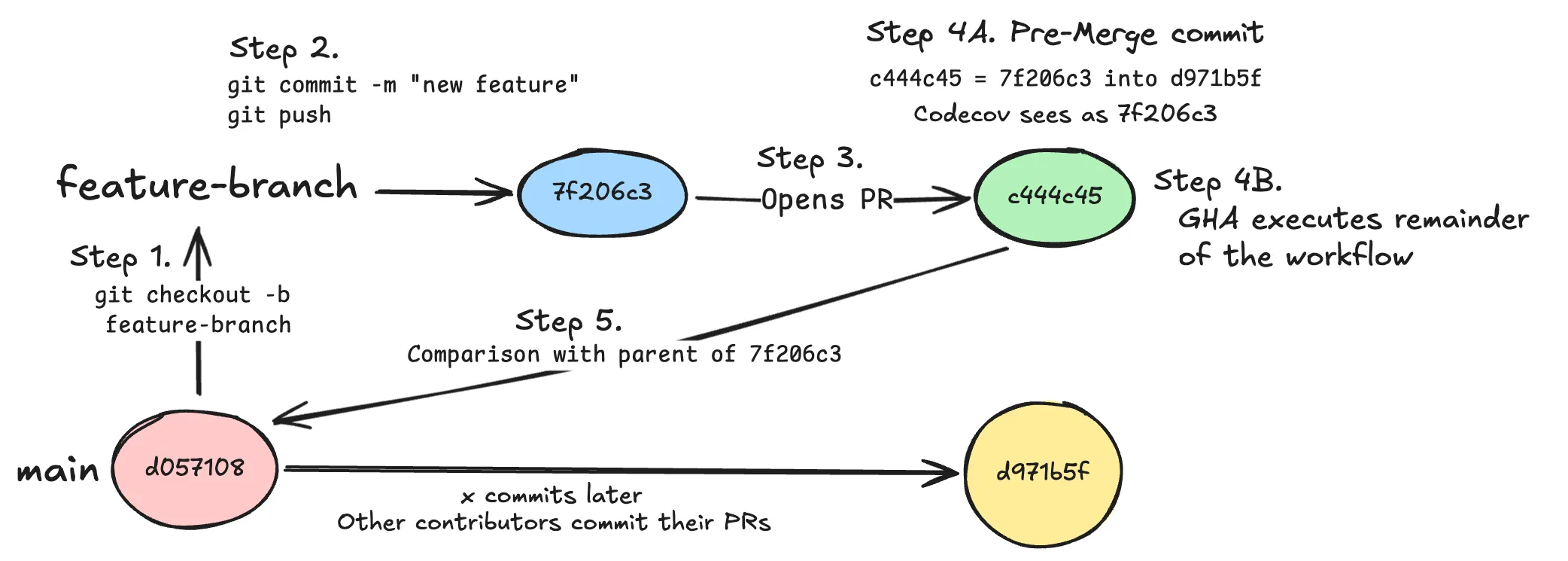
Lets break down what’s happening in this graphic:
- User checks out to their new feature branch from their repositories default branch that they will later attempt to merge their changes into.
- User has implemented their new feature and commits their changes, and pushes the changes to GitHub.
- User opens up a new PR on GitHub triggering their CI to run.
- Running GitHub Action workflow after PR is opened
actions/checkoutstep is ran checking out their changes and creating a merge commit based off of the users feature branch commit, and the current head commit of the branch that they have targeted with their PR.- Bundler plugin runs during application build and grabs the relevant Git information such as branch name, head commit SHA, etc. It then takes that information and uploads it alongside the bundle stats data to Codecov.
- Compare passed head commit with its direct parent commit.
So with this graphic and how Codecov compares against the parent commit you may be able to see the problem that we were facing. The problem arises when the action checkouts to the detached head (green circle) and uses the latest comparison branch head commit (yellow circle) as the base, however because Codecov sees the detached head commit (green circle) actually as the branch head commit (blue circle) it compares it against the original base commit (red circle) instead of the now correct base commit (yellow circle).
Solving Incorrect Base Commit SHA’s
So what is the solution here? Well, we are already grabbing the correct head commit SHA, why can we not just grab the correct comparison base commit SHA? It turns out, we can for the bundler plugins. It is not a giant leap away from how we grab the current correct head commit, and it was a fairly small implementation change.
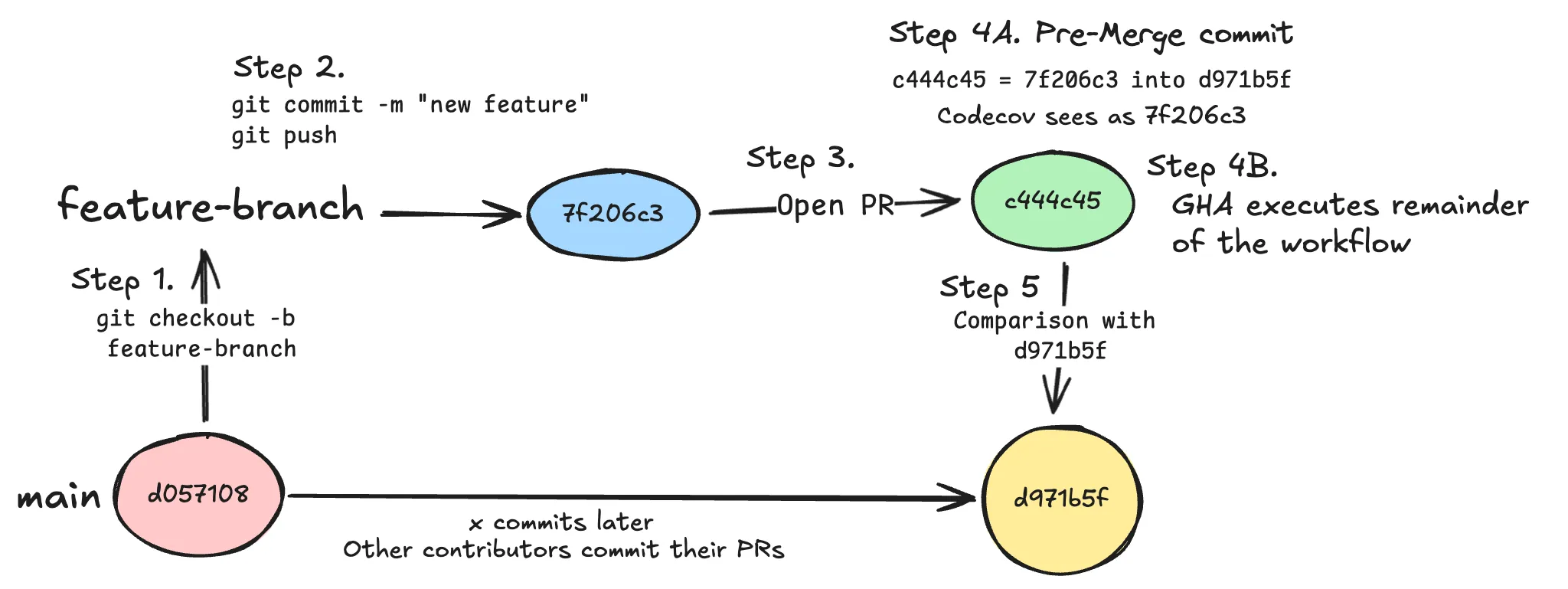
- User checks out to their new feature branch from their repositories default branch that they will later attempt to merge their changes into.
- User has implemented their new feature and commits their changes, and pushes the changes to GitHub.
- User opens up a new PR on GitHub triggering their CI to run.
- Running GitHub Action workflow after PR is opened
actions/checkoutstep is ran checking out their changes and creating a merge commit based off of the users feature branch commit, and the current head commit of the branch that they have targeted with their PR.- Bundler plugin runs during application build and grabs the relevant Git information such as branch name, head commit SHA, compare commit SHA, etc. It then takes that information and uploads it alongside the bundle stats data to Codecov.
- Compare branch passed head commit against passed comparison commit.
When it comes to the internal side of Codecov there are a few more complications that we run into and how we handle comparisons, as I mentioned earlier, we have a table of pull requests and in this table we store the base, head, and compare to commit SHA, however we cannot override this compare to SHA as it is the correct one for coverage comparisons. Okay, so can we just add a new field to the table? Well, we could, however the pulls table isn’t exactly “small” with millions of rows, which would require us to lock that table until the operation has completed. Instead we have decided to take a slightly different approach that is tailored to our bundle analysis setup. When users upload a stats report for the first time, it is sent directly to GCP and our “worker” will pick up the file and process it, with the resulting information being stored inside of a SQLite DB, any other bundle stats that are uploaded for a given commit are than merged into that same SQLite DB. It will be inside this SQLite DB where we will store the correct comparison SHA for bundle analysis, and as a precaution we will fallback to the pull request compare to commit SHA.