Mutation-testing our JavaScript SDKs
Have you ever thought about testing your tests? Check how good they really are at catching bugs? Welcome to the realms of test suite evaluation! Mutation testing (MT) is considered the gold standard when it comes to evaluating the fault detection ability (I’m going to stop with academic terms in a sec!) of your tests. In this article, we’ll explore what mutation testing is, why it’s a rather niche technique and what we learnt from using it on our JavaScript SDK codebase.
Intro to Mutation Testing
You probably heard of code coverage before, which comes in various flavours and granularities (statement, line, branch coverage, etc). Perhaps you use it in your codebase and you’re happy about that green >90% coverage badge in your repo. While that is great, coverage has a substantial limitation: It only tells you which units of code (e.g. lines) were executed during a test run. It tells you nothing about if the executed lines were actually checked or if—were you to introduce a bug into one of these lines—your tests would actually catch the bug. So playing devil’s advocate, you could say coverage really only tells you one thing with certainty: Which parts of your code are not covered by any test.
Let’s circle back to the part about coverage not telling you if an introduced bug would be caught. What if there was a tool that does exactly that? Enter mutation testing.
The idea of mutation testing is fairly simple:
- Make a slight modification to your codebase. (In MT terms: Apply a mutant operator to your code base.) For example, change an equality operator:
The resulting code is called a “mutant”.function isEven(num) { // return num % 2 === 0; // mutate to: return num % 2 !== 0; } - Run your tests against the mutant.
- If at least one of your test fails, crashes or times out, the mutant was killed.
- If all your tests still pass without a crash or timeout, the mutant survived.
- Repeat 1 and 2 until all possible mutant operators have been applied to your codebase or you reached a pre-defined maximum number of mutants.
After this virtual bloodbath, you can calculate a Mutation Score by dividing the number of killed mutants by the number of all created mutants. The score now tells you how likely it is that your tests would catch an actual bug.
Mutant Similarity Assumption
The entire concept of MT depends on the assumption that mutants are similar to actual bugs that programmers might introduce into the code base. Now the question is, is this true in reality? Luckily, engineers at Google publish papers about mutation testing every now and then. In one of them, they investigated the similarity assumption by comparing 15 million mutants against bugfix PRs. They found a high similarity of mutants to bugs, suggesting that the assumption does hold up. Does this translate to other code bases? It’s hard to say give a definitive answer, but it seems reasonable for most code bases. For the sake of experimenting, we decided to go ahead with a “yes”.
Performance
While the mutant similarity assumption is certainly a relevant caveat, what really keeps mutation testing from being widely adopted is its high performance impact. Running 1000s of tests on 1000s of mutants is computationally expensive - much higher than any kind of coverage calculation. Fortunately, modern MT tools provide optimizations that minimize the runtime as much as possible. For example, they use “per-test” mutation coverage to determine which tests cover a mutant and then, only execute this subset of all tests on the specific mutant. Similarly, modern MT tools chain multiple mutants into one modified code base and activate a specific mutant at runtime. This means that the modified code base doesn’t have to be re-built for every mutant, but instead only once at the beginning of the MT run.
More recently, we saw the light of incremental mutation testing, where mutants would only be created in changed code files vs in the entire code base. The idea is to establish a baseline from a previous mutation test, compute the diff or file changes since then and start an incremental MT run on the changed files. This significantly decreases MT runtime but is limited in accuracy, depending on how well tools are able to determine what actually changed.
JavaScript Tooling
When it comes to tooling in JavaScript for mutation testing, the by far most popular option is Stryker. Stryker is available for various languages, but for JS specifically it shines with support for all major test frameworks (with one unfortunate exception as we’d learn soon), support for per-test mutation coverage, chained mutants and even incremental mutation testing.
The general idea of Stryker is that you specify your MT configuration in a config file and it takes care of everything else, just like a conventional test framework. Similarly, you’ll also end up with a mutation test report coming in various flavours like terminal output of the mutation scores, JSON files with the results as well as a convenient HTML-based report which allows you to inspect all intricate details, like the created mutants and which mutants were (not) covered by which test.
Mutation-testing the Sentry JavaScript SDKs
Now let’s get down to business. Every year, Sentry celebrates “Hackweek”, a one-week period where everyone in the company can escape their actual work obligations and work on whatever project or idea they feel passionate about. I’ve always wanted to give mutation testing a try in a production code base, so for this year, I decided to spend my Hackweek experimenting with Stryker in the repo I work most in - Sentry’s JavaScript SDKs.
How we test our SDKs
Our Sentry JavaScript SDK repository is a monorepo, consisting of various packages that we publish to NPM. We create dedicated SDKs for all (semi) popular or hyped JS frontend and backend frameworks. These individual SDKs are built on top of more generic browser and server SDKs which in turn are built on top of a core SDK package. This results in a package hierarchy where one SDK is in fact made up of several SDK packages.
Given our SDKs are used by millions of developers, we go to great lengths (take a look at our CI config, we take length quite literally) in terms of testing to ensure we break folks as little as possible. We employ various testing techniques of different granularities:
- Every package has unit tests that test individual, package-specific behavior. On this test level, we want to cover individual package exports, edge cases as well as more complicated paths, of course with a sprinkle of general purpose tests. Basically, your typical unit test setup. We mostly use Vitest and Jest (we’re slowly moving away from it but it’s complicated).
- On the other end of the spectrum, we created a small army of End-to-End test applications. These are small standalone apps built with various frameworks in which we test our actual NPM packages. Testing here is done on a higher level, as we mostly only check the resulting payloads of errors or other events our SDKs send to Sentry, but they catch a surprisingly high number of bugs and have proven themselves valuable more than once. For E2E tests, we rely on Playwright, which we like a lot.
- Sitting comfortably in between unit and E2E tests, we run integration test suites against our base browser and Node SDKs to cover more wholistic scenarios. In these tests, we also check for resulting payloads but our SDK setup is far more flexible. Meaning, we can test against a variety of differently configured SDKs, giving us a lot of flexibility to check unit-test-like scenarios (with edge case configs) in a more wholistic manner. We use Playwright for browser and Jest for Node integration tests.
Implementing Mutation Testing
To get started with mutation testing, we created a shared Stryker config with the base parameters, such as the report formats, as well as some MT behavior-related parameters. For example, to minimize the performance impact, we chose to selectively run tests based on the per-test coverage determined by Stryker and ignored static mutants.
We started opting individual packages into MT by adding Stryker to these packages and importing the shared config. Adding Stryker was really easy in almost all cases as the Stryker runner just works (TM). Only in some packages, where we for example use the JSDOM test environment, we had to manually declare the respective Stryker test environment.
Now, as we already established, MT runtime is a concern. So we were specifically interested in how long MT runs would take for individual packages as well as how long it would take overall in CI. Could we run it on every PR? Every day? Once a week?
To find this out we used … well … Sentry. More specifically, Sentry’s tracing and performance monitoring capabilities, as well as dashboards to keep track of the MT results. We replaced the simple npx stryker command with a small Node script that would initialize the Sentry Node SDK, use the Stryker JS API to start the MT run and wrap a couple of Sentry spans around the test operations.
Ultimately, we added a new script to the packages’ package.jsons, so that engineers can start an MT run with the comfort of a simple yarn test:mutation command.
Mutation Test Results
So, how did our tests do? Well, it’s complicated. So let’s talk about mutation test results, our interpretations as well as about runtime performance. We opted 12 of our packages into MT and got rather mixed results. Take our core SDK package as an example:
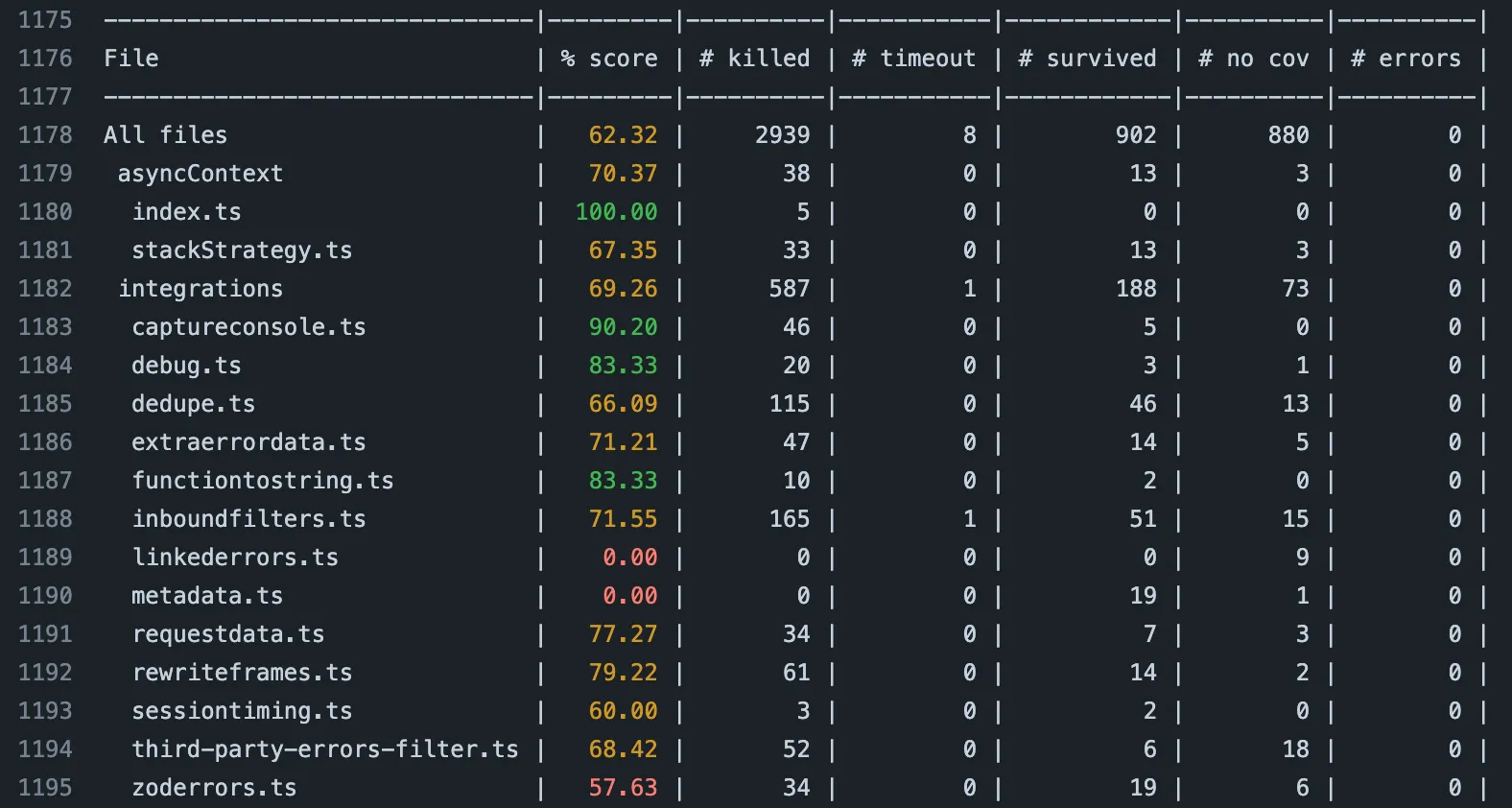
We achieved a mutation score of 0.62, meaning 62% of the created mutants were killed. Not too shabby but not too great either on first glance. We took a closer look at the results and found two things:
- A good portion of created mutants survived. In Stryker-terms, this specifically means that at least one test covered the mutant but did not detect it. A fair amount could be attributed to edge case code paths, where we’d log warnings (something we just didn’t test on too much) or early return in a function. The importance varied from “We should definitely cover this” to “sure, would be nice to cover but not necessary”. Some other created mutants were simply a bit unrealistic, for example when an empty string was replaced with a
"Stryker was here"constant. Some of these cases would have been caught by TypeScript at build time, due to us using string literal types quite a bit. - In addition to survived mutants, mutants in an almost equal number were not covered by any unit test. We were a bit surprised about this number, but it makes sense (bear with me!). It’s important to keep in mind that creating mutants everywhere in our code base is realistic, given bugs will sneak the easiest into uncovered code.
Does this mean we have a massive test coverage problem? No. As mentioned earlier, we not only use unit testing but also integration and e2e tests. Many of the untested areas in the core package, are covered by integration and e2e tests. While these tests don’t explicitly check the core package but higher-level packages, bugs in the core package would manifest very likely by altered SDK payloads which we check on in these higher-level tests.
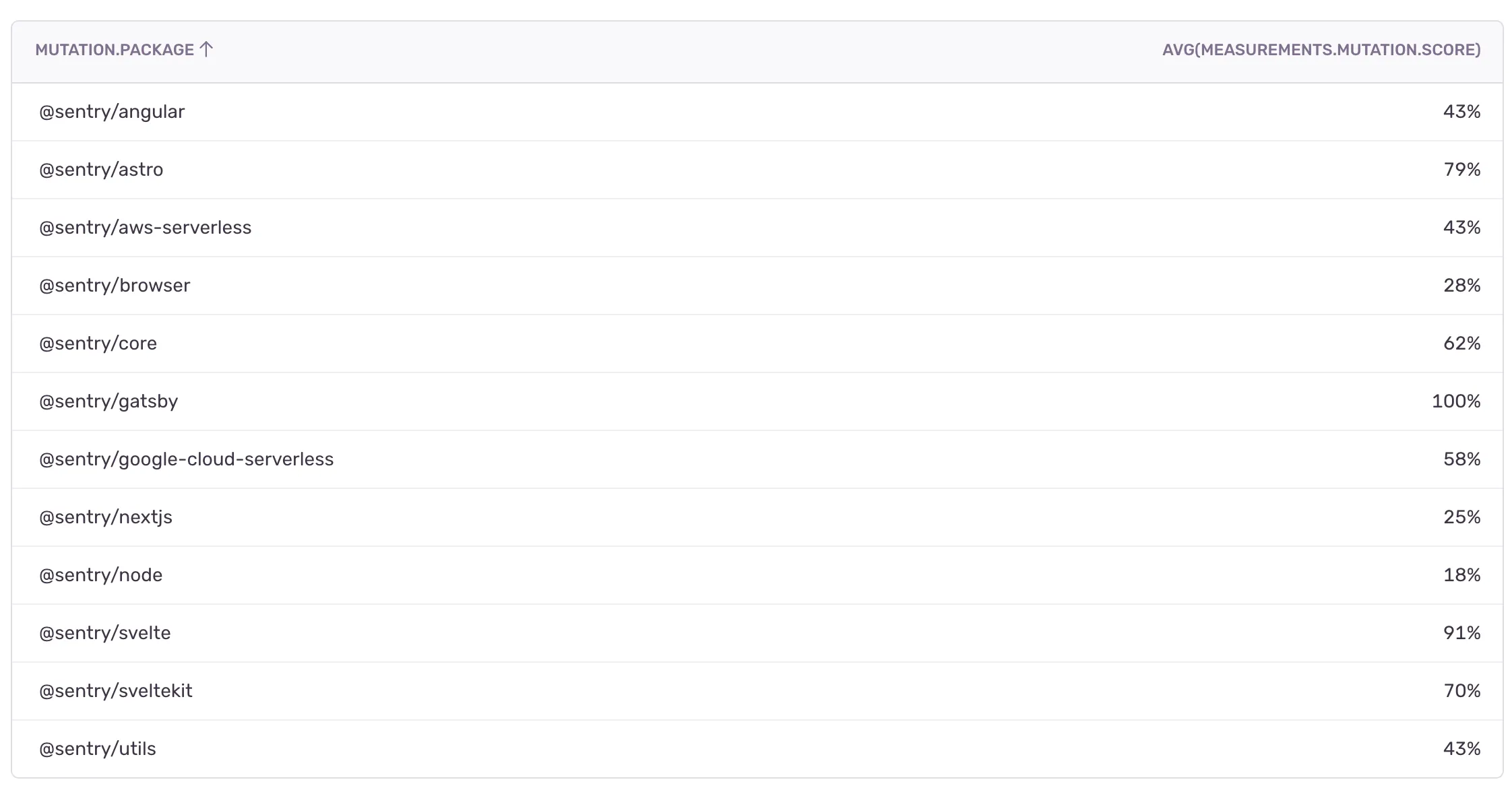
This trend is confirmed to an extent by the mutation scores of higher level packages. With some outliers, higher level packages, like our browser package or our NextJS package (inheriting both from Browser and Server SDK packages), had lower mutation scores than the core package. However, for these higher-level packages we have substantially more E2E and integration tests, which evens out the missing coverage of unit tests.
The obvious problem was that we couldn’t get MT to run in our integration and E2E tests. Stryker unfortunately doesn’t support our testing framework of choice, Playwright. So for us this means, that the current state of mutation testing in our repo doesn’t show the complete picture. It’s important to keep this in mind as it explains the lower scores despite us having thousands of tests in the entire repo.
While this is an unfortunate limitation, we could also identify some areas that should be better tested. Which is great because this means to an extent, mutation testing did what it was supposed to do: It showed us how good our tests are at catching bugs and where we should do better. Just not for all tests.
Performance
As for mutation testing runtime, we were quite positively surprised. Larger packages like our core and node packages took on average 20-25 minutes to run in our GitHub CI.
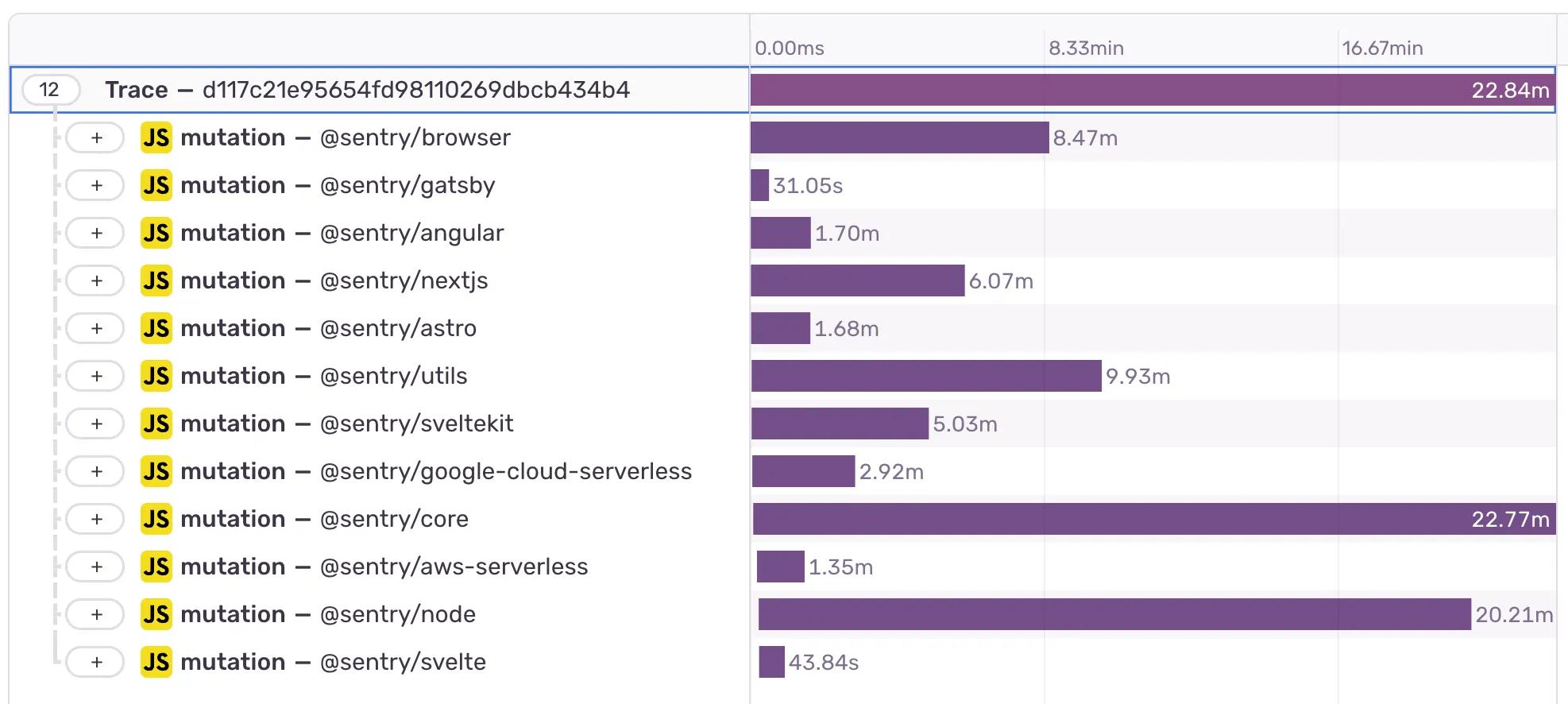
Given we only mutation-tested on a package level, we could easily parallelize running the tests in individual jobs. Consequently, a complete mutation test run across all packages wouldn’t take much longer than the longest lasting individual run:
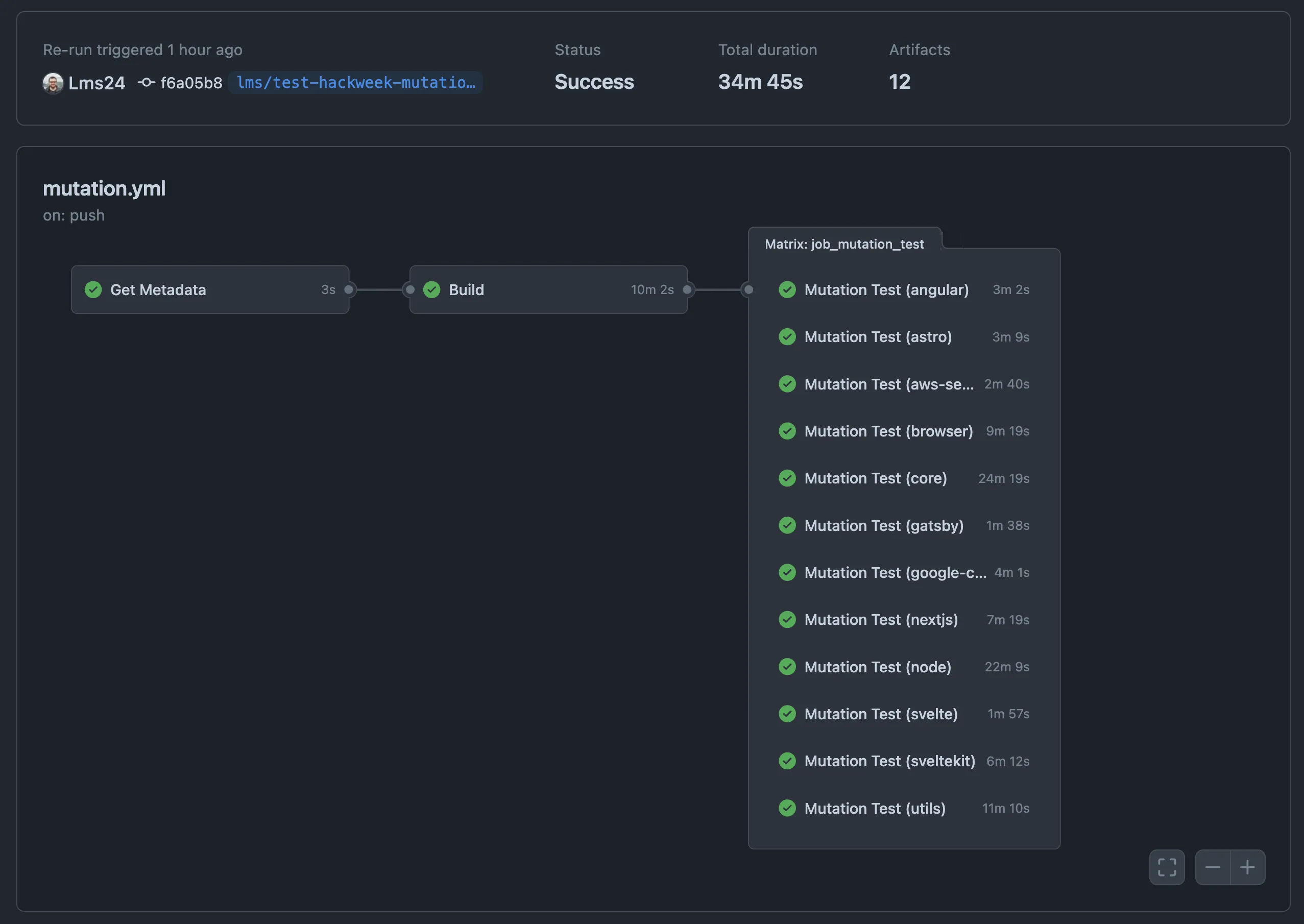
Factoring in the dependency installation and build time before the test run, a complete CI run takes around 35-45 minutes, which is shorter than we anticipated. It is definitely too long to run this on every PR or push. However, given the limitations we encountered the value gain wouldn’t be substantial enough to justify this anyway. Therefore, we decided to run our mutation testing setup once every week to track the score over time. We’ll use Sentry’s Dashboards and Alerts features to for example alert us when there’s a significant drop in mutation score.
As a further experiment, we switched from Jest to Vitest in the Core SDK package. While the conversion was relatively easy, it reduced the MT runtime from 60 minutes to now much more manageable 25 minutes. We generally want to switch over to Vitest and already did so in several packages. Unfortunately, given our Node SDK still supports Node 14 and hence we test on Node 14 as well, we cannot convert all our packages to Vitest yet. This is because Vitest only supports Node 18 and above. We found it also works for us in Node 16, but unfortunately not in Node 14. So Jest will stay a bit longer with us than we hoped.
Conclusion
Let’s wrap this lengthy blog post (congrats if you made it this far!) up with some learnings we had from experimenting with mutation testing.
Mutation Testing is a great asset for checking the quality of tests and we definitely found some areas where test improvements would be beneficial. In our particular monorepo and testing setup, where we cover a lot of test scenarios in E2E and integration tests, we unfortunately came across some limitations. This manifested itself by the fact that the mutation scores were lower than anticipated but also simply did not fully represent our combined test suites’ ability to detect bugs.
Performance-wise, we were positively surprised about the runtime, given that a complete MT run on all packages takes less than an hour. We’ll continue to run mutation testing once every week to track the mutation score and see how it develops over time.
Future Improvements
Well, Hackweek is over and so is the time we can spend on experimental tech like MT. But there are definitely some interesting things to try out in the future.
Running Stryker on E2E and Integration tests
As a thought experiment, let’s assume we’d write a custom Stryker runner for Playwright (Stryker is open-source so it would be possible to try this). We’d encounter several challenges if we wanted to use this runner for MT in our integration or e2e test setup:
- We wouldn’t actually be interested in creating mutants on the test apps’ source code. Instead we’d need to configure it to create mutants of the test apps’ dependencies, more specifically on the
@sentry/*SDK packages. At this time, the SDK code is no longer the original source code but it’s transpiled to JS. This poses new questions, for example:- Does the original Mutant Similarity Assumption still hold up equally well?
- Can we map back the transpiled code 1:1 to our original source code to correctly attribute the MT results in the report?
- Can Stryker in this configuration still correctly chain multiple mutants together? If not, we’d probably need rebuild the test app for every mutant, resulting in much prolonged MT runtime.
- As a possible alternative, if we cannot run Stryker on dependencies, we’d need to modify the actual source code, rebuild all affected SDK packages and finally of course the test app as well. The resulting MT runtime would probably be infeasible.
- If we find some ways to figure out these MT setup and runtime problems, we’d still need to investigate what the resulting mutation score will tell us. Can we attribute the score back to individual packages? If so, how? Can we somehow calculate a combined mutation score over the entire repository?
As you can see there are a lot of unknowns here. It would be great to give this a try but the challenges are definitely hard to overcome. Perhaps we can start with writing and contributing Playwright Support for Stryker. Next Hackweek is only a year away :)
Incremental Mutation Testing
Something that might be more easily achievable is incremental mutation testing. The idea would be to only create mutants on the changed files in a PR and run Stryker on these files. While in theory this sounds good, we’d still need to answer some questions as well:
- Can Stryker accurately detect changes across multiple packages?
- The Playwright and E2E/Integration testing limitation still applies, so how useful would this even be?
- What can we take from the score and does it provide value for engineers? Can we meaningfully show test deficiencies in the GitHub PR UI?
Mutation Testing in CodeCov
This is not a feature announcement! Just an idea I had while working on this experiment. It’d be nice to have a clean and polished interface like CodeCov to keep track of mutation test results over time. Stryker’s dashboard is a first step but having all our test metrics under one hood would arguably be even better. Maybe for next year’s hackweek we could take a dive into CodeCov’s code base.