Keeping Up With the Python Ecosystem
The Python SDK is one of Sentry’s biggest SDKs, both usage-wise and also in terms of how many packages it provides out-of-the-box instrumentation for. At the time of writing, it has more than 60 integrations, from web frameworks to task queues to AI libraries.
Adding an integration is just the beginning, though. We also need to make sure it keeps working as time goes on, as new Python versions come out, and as new versions of the package itself are released, while also ensuring the integration doesn’t break when used with the lowest supported version.
Thing is, integrations are written for a package at a certain point in time. We often need to go pretty low-level, way past any public API surface, to integrate with a package. This is essentially lawless territory where no stability guarantees apply: internals can change at any point. And even if we integrate via a higher-level API, that can change, too; just usually with a bit more notice.
While we could make things way easier for ourselves by just always supporting the new shiny thing, that’s not how we roll. It’s not our job to dictate to users which package versions they ought to be running if they want to use Sentry. If reasonably possible, we’ll keep supporting package versions for years.
The Setup
Each of our integrations comes with its own test suite. We use the delightful tox for managing our test matrix, which is stored in a big tox.ini file. tox allows you to define multiple targets to test, and they all get their own virtualenv with their own dependencies. You can also test on multiple Python versions.
All in all, tox fits our use case perfectly, and we’ve been using it for a while. To illustrate, the envlist part, which defines all test targets, used to look something like this for two of our integrations (Spark and Starlette):
# Spark
{py3.8,py3.10,py3.11}-spark-v{3.1,3.3,3.5,4.0}
# Starlette
{py3.7,py3.10}-starlette-v{0.19}
{py3.7,py3.11}-starlette-v{0.24,0.28}
{py3.8,py3.11,py3.12}-starlette-v{0.32,0.36,0.40}And the corresponding dependencies part looked like this:
# Spark
spark-v3.1: pyspark~=3.1.0
spark-v3.3: pyspark~=3.3.0
spark-v3.5: pyspark~=3.5.0
# TODO: update to ~=4.0.0 once stable is out
spark-v4.0: pyspark==4.0.0.dev2
# Starlette
starlette: pytest-asyncio
starlette: python-multipart
starlette: requests
# (this is a dependency of httpx)
starlette: anyio<4.0.0
starlette: jinja2
starlette-v{0.19,0.24,0.28,0.32,0.36}: httpx<0.28.0
starlette-v0.40: httpx
starlette-v0.19: starlette~=0.19.0
starlette-v0.24: starlette~=0.24.0
starlette-v0.28: starlette~=0.28.0
starlette-v0.32: starlette~=0.32.0
starlette-v0.36: starlette~=0.36.0
starlette-v0.40: starlette~=0.40.0You can see we test each of the integrations on a bunch of Python versions, as well as a handful of package versions. In the olden days, when things were simpler and we had much less integrations, it was kind of feasible to maintain this kind of configuration by hand.
Making sure we always support the lowest declared version of a package was trivial as this (almost) never changes: just add the lowest version to the test matrix when you first start testing the integration and never remove it.
However, reacting to new package and Python releases by adding them to the test matrix required a lot of manual effort and things often fell through the cracks. Most packages don’t have a set release schedule and new releases can’t be anticipated. And even if some projects like Django have release dates defined ahead of time, without any process in place it was still very easy for us to miss manually updating the test matrix with them.
First Improvements
The first improvement we made since it was very low-effort was subscribing to a service that notified us when a new package version appeared on PyPI. We would receive these notifications on Slack and a member of the team needed to act on this manually: go to tox.ini and add the new release if it was notable enough (e.g. a new major). Not a great process, but it was a first step.
We soon improved on this by adding a new “latest” test target to each of our test suites. It would simply install the latest available version of each package and run the test suite against it. (Until then, we had only been testing pinned versions.) This new “latest” category of test targets would run on every PR, with the associated GitHub action check not being mandatory. The idea was that PRs shouldn’t be blocked on unrelated changes, but that we would be notified if an integration stopped working with the latest release. We would then address this in a separate PR. This improvement brought some visibility into what had been a blind spot for a long time.
The problem was that aside from this dynamic “latest” test category, the rest of the test matrix was still very much hardcoded. So we’d be testing for instance versions 1.24, 1.27, 1.30 of a package that was already potentially on, say, version 1.94. While 1.94 would be tested in the “latest” test target as long as it was the latest release, we were disproportionately focusing on older versions, and potentially unaware of breakages between 1.31 and 1.93.
Make Computer Do Things
With the number of integrated packages already quite high and many of them moving quite fast (looking at you, AI frameworks), updating the hardcoded configuration by hand would’ve been tedious and unmaintainable. Luckily enough, we’re lazy and so we quickly realized we can offload all of this to a computer.
So began the populate_tox.py script, internal codename toxgen. The general idea is:
- Automatically poll PyPI for each of the packages we have an integration for to find out the full range of releases we support, including any recent releases.
- Automatically pick out a representative sample of releases to put in the test matrix.
- We should always test the lowest and highest supported version.
- Optionally, we can add a set of roughly evenly spaced releases in between.
- If we support multiple majors, make sure to test at least one release in each major.
- If there is a recent prerelease, test that, too.
- Run this script periodically in a GitHub action and have it submit a PR with the updated test matrix.
- Look at the PR once it’s been submitted, fix incompatibilities if the new test matrix uncovers issues, and finally merge.
Encoding Restrictions
Though the idea might be simple, implementing it has not been a straightfoward process. A lot of our integration tests have very specific test dependencies. See, for example, our old dependency configuration of the httpx test suite:
httpx-v0.16: pytest-httpx==0.10.0
httpx-v0.18: pytest-httpx==0.12.0
httpx-v0.20: pytest-httpx==0.14.0
httpx-v0.22: pytest-httpx==0.19.0
httpx-v0.23: pytest-httpx==0.21.0
httpx-v0.24: pytest-httpx==0.22.0
httpx-v0.25: pytest-httpx==0.25.0
httpx: pytest-httpx
# anyio is a dep of httpx
httpx: anyio<4.0.0
httpx-v0.16: httpx~=0.16.0
httpx-v0.18: httpx~=0.18.0
httpx-v0.20: httpx~=0.20.0
httpx-v0.22: httpx~=0.22.0
httpx-v0.23: httpx~=0.23.0
httpx-v0.24: httpx~=0.24.0
httpx-v0.25: httpx~=0.25.0
httpx-v0.27: httpx~=0.27.0
httpx-latest: httpxIf you have package versions hardcoded in your test matrix, it’s easy to just hardcode the dependency versions as well, as we did above. But when moving to the automated approach, we needed a way to encode which dependency versions are needed for all possible package versions (since any of them might be potentially picked).
We settled on a configuration file for toxgen that encodes dependencies like so:
TEST_SUITE_CONFIG = {
"httpx": {
"package": "httpx",
"deps": {
"*": ["anyio<4.0.0"], # this will be installed for all httpx targets
">=0.16,<0.17": ["pytest-httpx==0.10.0"], # for httpx between 0.16 and 0.17, install pytest-httpx==0.10.0
">=0.17,<0.19": ["pytest-httpx==0.12.0"],
">=0.19,<0.21": ["pytest-httpx==0.14.0"],
">=0.21,<0.23": ["pytest-httpx==0.19.0"],
">=0.23,<0.24": ["pytest-httpx==0.21.0"],
">=0.24,<0.25": ["pytest-httpx==0.22.0"],
">=0.25,<0.26": ["pytest-httpx==0.25.0"],
">=0.26,<0.27": ["pytest-httpx==0.28.0"],
">=0.27,<0.28": ["pytest-httpx==0.30.0"],
">=0.28,<0.29": ["pytest-httpx==0.35.0"],
},
},
}The toxgen script then reads this config and checks any picked version against it, automatically generating the dependency restrictions in tox.ini:
httpx: anyio<4.0.0
httpx-v0.16.1: pytest-httpx==0.10.0
httpx-v0.20.0: pytest-httpx==0.14.0
httpx-v0.24.1: pytest-httpx==0.22.0
httpx-v0.28.1: pytest-httpx==0.35.0In addition to being able to specify dependency versions, we also needed a way to encode other restrictions. For instance, sometimes we only want to run a test suite on specific Python versions. Or, for some packages, we were fine only testing the oldest and newest version; for others, we wanted a number of versions in between. All of these restrictions and tweaks made it into the config format.
Step by Step
Some integration tests were easier to migrate than others. Some didn’t even have any additional test dependencies, removing the need for defining deps, the most annoying part of the config, completely. Those were the ones we migrated first.
For a while, we had a dual setup with some not-yet-migrated integrations using the old system (hardcoded pinned versions plus a “latest” target), while the rest of the test matrix was already being auto-generated by toxgen.
Once we finished the migration fully, only one part was missing: making the script run periodically on the repo and submitting a PR with the updated test matrix each time. We eventually made that happen too: this is an example PR.
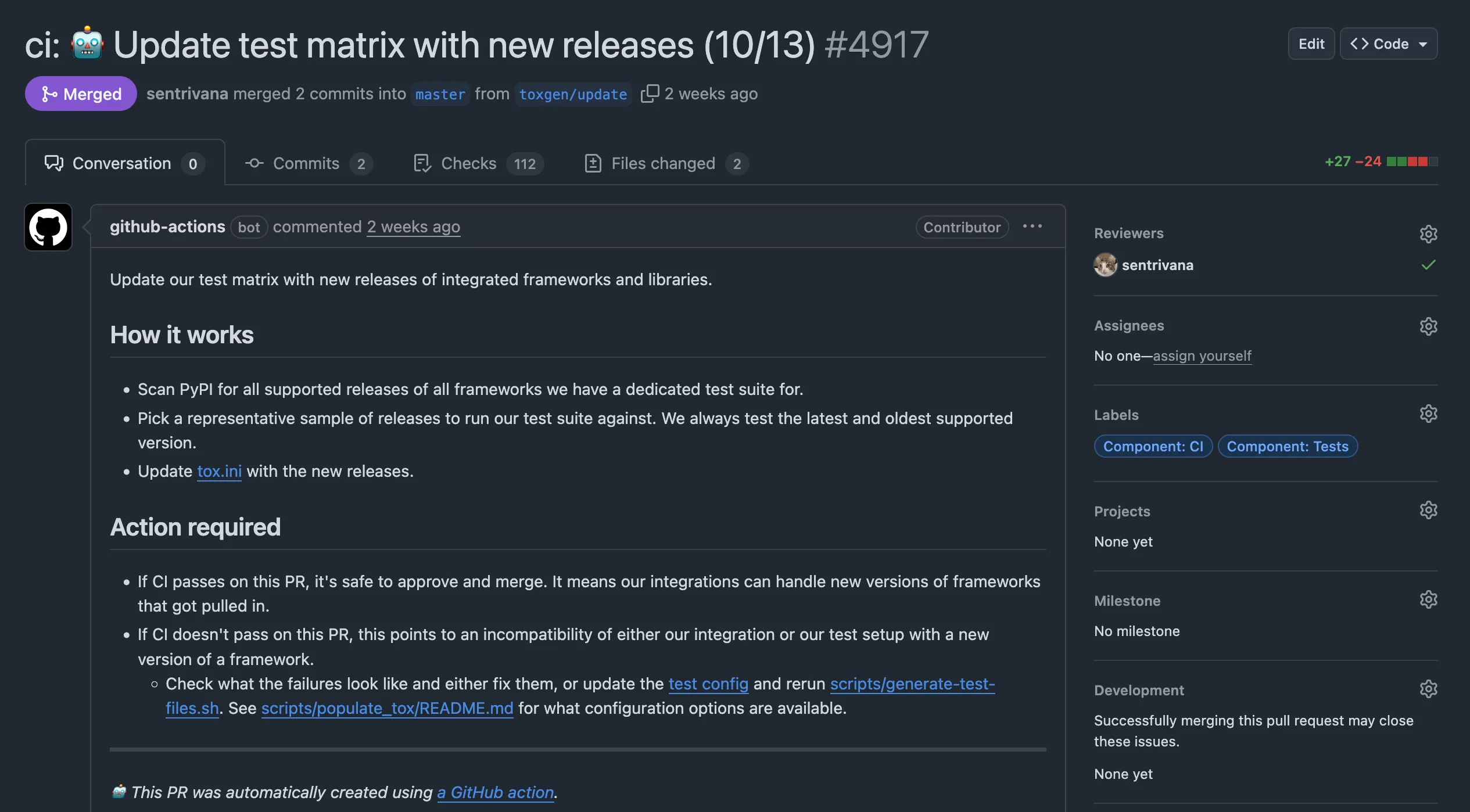
Developer Experience
In terms of developer experience (DX), toxgen hasn’t been without some downsides, namely:
- Just like any other auto-generated file,
tox.iniis prone to merge conflicts if it’s been modified both on the target branch and the PR branch. These merge conflicts can’t be solved manually; toxgen has to be rerun and the newtox.inicommitted. - If someone changes
tox.inimanually (for instance because they don’t know it’s auto-generated), their changes will be overwritten the next time the file is regenerated. The obvious (and obviously infallible) way to combat this is a big all-caps warning in the file. In addition to that, for a while we also had a CI check that attempted to detect this sort of desynchronization. However, it proved to be more trouble than it was worth. Due to the config file’s dynamic nature it’s hard to tell apart “good” changes (e.g. new versions that toxgen pulled in) and “bad” ones (someone editing the file directly). We tried a couple of iterations on this but ultimately decided to forego checking this automatically.
Overall though, DX has improved:
- Folks contributing a new integration don’t have to manually come up with a test matrix, the script will do that for them as long as they add the name of the new integration in a couple places.
- We are not blocked on unrelated PRs and releases due to failures resulting from the regenerated matrix as the fallout is contained to the one weekly PR.
- There is a small utility shell script that takes care of updating our whole CI setup at once, regenerating
tox.iniwith toxgen and then running another script that generates the CI YAML config for all our test groups.
Sidenote to the last bullet point above: The way our CI testing pipeline works past the tox part would make for its own blog post, so I’ll not go into the hairy details here.
Impact
Arriving at this point was a lot of work, but work which has already started paying off. To sum up, we can now rest easy because we’re testing each of our integrations against:
- a reasonable set of Python versions
- the oldest supported version of the package to prevent regressions
- a small set of versions in between the lowest and highest supported
- the newest release of the package to detect incompatibilities early
- as well as any relevant prereleases so that we can support new stable releases on day one
Especially the last two bullet points above have had a big impact. While manual work is still required to update our integrations in case a new version breaks it, we discover this early and can address it quickly.
Maybe in the future we can delegate the initial fix to AI. Something to explore going forward to make the whole process even more hands-off.